|
On this page:
|
On the Data tables 1 page:
|
|
On the Data tables 2 page:
|
On the Data tables 3 page:
|
Inherited spreadsheet problems
Data cleaners mainly work with plain text tables. Often these tables come from spreadsheets, either by export, conversion or copy/pasting. These derived data tables sometimes inherit problems from their spreadsheet originals. Below are some inherited problems I've found in my data auditing work. With some exceptions (see below), you can fix the problems if you have access to the original spreadsheet. (See also Tidy data tables.)
Reformatted dates, numbers and codes. These are well-known and common headaches for spreadsheet users as well as for data cleaners. For example, the spreadsheet displays the date as "5-Jun-2021", but the derived table has "6/5/2021" or "44352". Leading zeroes tend to disappear: the spreadsheet shows "0021437" but the text file has "21437".
A data cleaner can sometimes spot and fix reformatting issues like these without reference to the original spreadsheet, but it's best to query the data compiler before making changes.
Unintended dates and times. If the data compiler hasn't noticed what happened, the data table may contain irrelevant date and time entries. For example, the intended data item might have been the code "12/2", which on entry into the spreadsheet became the date "12/2/2022". Or "2019:23:0020" (a code) became "2019:23:20" (the time format [h]:mm:ss). There is no simple fix for these confusions and it's best to consult the data compiler about suspicious entries.
Field shifts. Blocks of data items may have been shifted into fields where they don't belong, perhaps when a copy/paste was done incorrectly. Field shifts can usually be detected as inappropriate entries with a field tally.
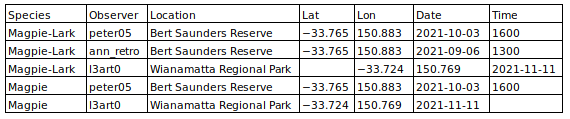
Because a field shift can overwrite data items, it's best to query the data compiler before attempting a fix.
Superfluous fields. I usually see this problem in CSVs, like this one:
Fld1,Fld2,Fld3,,,,,,,
aaa,"b, b, b",ccc,,,,,,,
ddd,,"ff, f",,,,,,,
ggg,hhh,,,,,,,,
Deleting the superfluous fields isn't as straightforward as it looks, because some end-of-line commas might be valid field separators. In the example above (the file "demo"), a valid end-of-line separator is highlighted in yellow. A practical strategy is to count the number of trailing commas in the header line, then delete that number of commas from the end of every line:
Commands to remove superfluous end-of-line commas from CSV
foo=$(awk -v FS="[^,]+" 'NR==1 {print length($NF)}' demo)
sed -E "s/,{${foo}}$//" demo
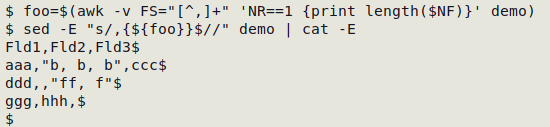
More information here.
Fill-down errors. If filling down in a spreadsheet has overwritten data items by mistake, the result may be impossible to detect. Another kind of fill-down error is easily spotted, as in this example, found in a tally of a geodeticDatum field:
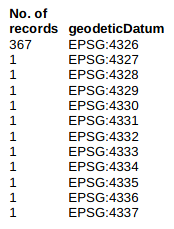
When the data item "EPSG:4326" was filled down it was also incremented by one in each succeeding spreadsheet cell. To find incrementing fill-down errors I use the "ifder" function. It takes as its argument a single field in which this error might occur, e.g. ifder <(cut -fN table), where N is the field number in the tab-separated table.
Function to check for incrementing fill-down errors in one field of a data table
ifder () { sort -V "$1" | uniq | awk -v FPAT="[0-9]+$" '/[0-9]+$/ {head=substr($0,1,length($0)-length($1)); tail=$1; if (head==hbuf && tail==(tbuf+1)) print hbuf tbuf ORS $0; hbuf=head; tbuf=tail}' | sort -V | uniq; }
Some of the "ifder" results may be valid entries, but the "ifder" result is a good starting place for a careful check. More information here.
Date twins. This is a problem peculiar to Microsoft Excel, which has used two different date systems. One system appears in most Excel versions, and another in early versions of Excel for Mac. When records from the two different date systems are mixed, there can be "duplicate" records separated by 1462 days.
Finding these Excel date twins isn't easy. One such search is described in this BASHing data post.
Formula artifacts. Part of a formula may appear in a data item. This is an uncommon and easily spotted problem. The following example appeared in a tally of a scientific name field:
13 | Calliblepharis ciliata (Hudson) Kützing, 1843
3 | Calliblepharis jubata (Goodenough & Woodward) Kützing, 1843
1 | Caulacanthus ustulatus (Mertens ex Turner) Kützing, 1843
1 | Ceramium Roth, 1797
1 | Chondracanthus acicularis (Roth) Fredericq, 1993
21 | Chondrus crispus Stackhouse, 1797
22 | Chondrus crispus StackhouseG188:O188, 1797
1 | Cladostephus spongiosus (Hudson) C.Agardh, 1817
1 | Codium Stackhouse, 1797
1 | Cryptonemia J.Agardh, 1842
1 | Cystoseira tamariscifolia (Hudson) Papenfuss, 1950