TSV This marker means that the recipe only works with tab-separated data tables.
A data auditing procedure
Check and fix if needed:
- character encoding
- structure (TSV?)
- gremlins
- Windows line endings
- broken records
- blank records
- empty fields
- character encoding failures
- excess whitespace
- multiple versions of the same character
- combining characters
- unmatched brackets
- correct and consistent formatting (names, dates, latitude/longitude, measurement units etc)
- inappropriate data items in a field
- truncated data items
- disagreements between fields
- missing but expected data items
- duplicates
- partial duplicates
- pseudo-duplicates
- related-field issues
...and anything else you notice while doing these checks, especially from field tallies!
Reporting results
If a data table has only been audited (not cleaned), a report can be based on results of the various checks done (see above) as documented in the auditing log. My practice in reporting is to group the results by problem, rather than review the table problematic-record by problematic-record.
If a data table has been cleaned, the "reportlist" script (below) will generate a before-and-after report. The script should only be used after any records have been added, deleted or checked and fixed for breaks, as the script assumes that the before-and-after tables have the same number of records and the same number of fields, in the same order.
The "reportlist" script takes as its two arguments the "before" and "after" versions of the data table and prints the results to screen (screenshot below). It also generates a time-stamped file of results called table-changes-[current date and time] in the working directory.
Script to list changes by line (record) and field TSV
#!/bin/bash
stamp=$(date +%F_%H:%M)
paste "$1" "$2" > merged
totf=$(head -1 "$1" | tr '\t' '\n' | wc -l)
awk -F "\t" -v f="$totf" '{for (i=1;i<=f;i++) if ($i != $(i+f)) print "line "NR", field "i": ["$i"] > ["$(i+f)"]"}' merged \
| tee "$1"-changes-"$stamp"
rm merged
exit 0
For example, here's an original table, "demo_old":
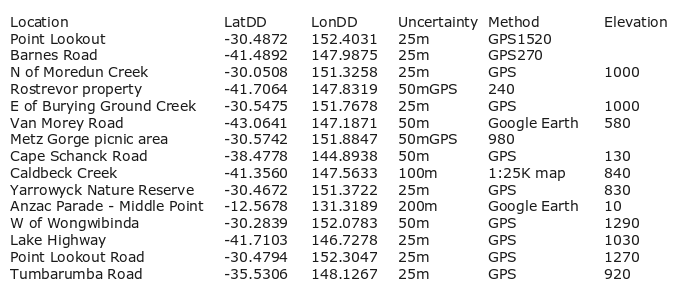
And here's the cleaned version, "demo":
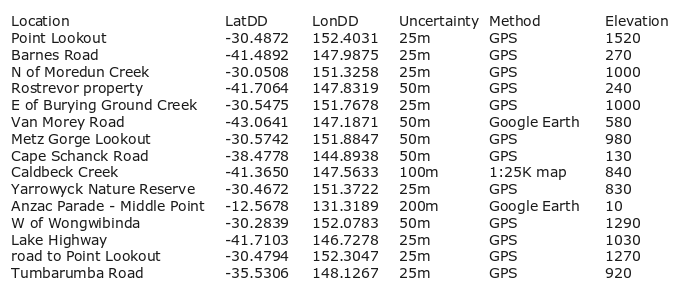
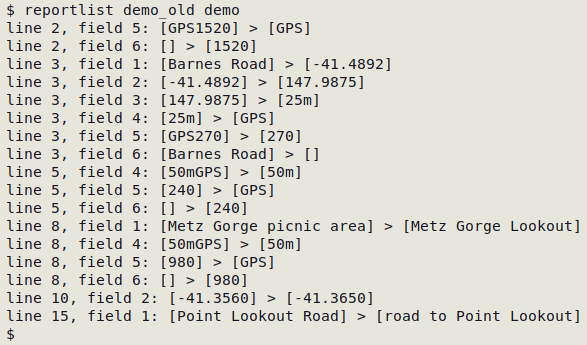
If the data table has a unique ID field, a better reporting script is "changes", below. To use the script, first back up the table to be edited by copying it to a table with a different name. For example, an "event.txt" table might be copied to "event-old.txt", or "event-v1.txt" or "event-2024-10-06.txt". Next, make any needed edits to data items in the original table, and save the edited table with the original table name. Run the script with the command
changes [backed-up table] [edited table] [number of ID code field]
In the example below, I've made edits in several records in a TSV called "event.txt". I copied the table to "event-old.txt" before editing, and "event.txt" after editing was saved with the original name, "event.txt". The unique ID field eventID was field 1 in this table. Note that the two edits in eventID "TAS-event-3076" are shown separately.
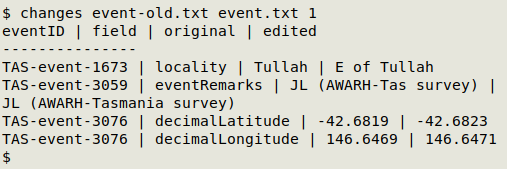
The changes script also built the table "event.txt-edits-2024-08-15T15:43:58.txt" in the same directory as "event.txt". In a text editor, the editing report looks like this:
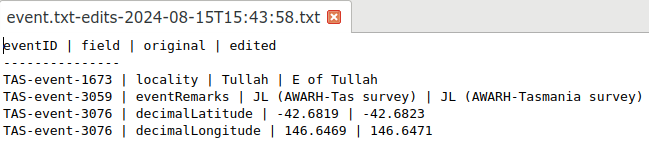
The changes script only shows edits within data items. If you are editing a table by adding, deleting or moving fields, or by adding, deleting or moving records, make these changes (and document them) before doing data item edits and reporting them with changes.
Script to list changes by unique ID field and edited field TSV
#!/bin/bash
paste "$1" "$2" > merged
FN=$(awk -F"\t" 'NR==1 {print NF/2; exit}' merged)
awk -F"\t" -v fn="$FN" -v idfld="$3" \
'NR==1 {for (i=1;i<=fn;i++) a[i]=$i; \
print $idfld FS "field" FS "original" FS "edited\n"} \
NR>1 {for (j=1;j<=fn;j++) if ($j != $(j+fn)) \
print $idfld FS a[j] FS $j FS $(j+fn)}' merged \
| sed 's/^$/---------------/;s/\t/ | /g' \
| tee "$2-edits-$(date +"%Y-%m-%dT%X").txt"
rm merged
exit 0