TSV This marker means that the recipe only works with tab-separated data tables.
Tally single field
The most-used function in my data auditing work is "tally". It takes all the data items from a single field in a tab-separated table except the one in the header line, then sorts the items, uniquifies them and reports their frequencies. The function takes table name and field number as its two arguments. (Field numbers are obtained from the "fields" or "fieldlist" functions.) A scan of "tally" results will reveal character, structure and format problems in a field, as well as pseudo-duplication.
Sort, uniquify and count all the data items in a field TSV
(The optional sed command tweaks the output from uniq -c, left-justifying the number and separating it from the uniquified data item with a tab.)
tally() { tail -n +2 "$1" | cut -f"$2" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/'; }
I run "tally" sequentially on a series of fields, usually on a working version of the data table from which empty fields have been removed. To move from one field to another, I up-arrow to repeat the command, then backspace the old field number and replace it with the new field number. If I expect the field to have many different data items, I pipe the output of "tally" to less for paging.
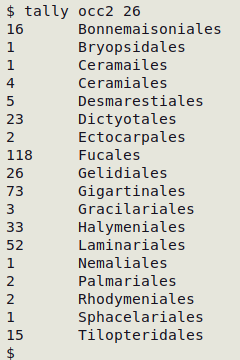
Below is a tally of the "order" field (field 26) in the table "occ2"; one of the "Ceramiales" entries is misspelled:
An alternative to paging through a long tally with less is to print just the first and last 10 lines with toptail.
Pattern matching
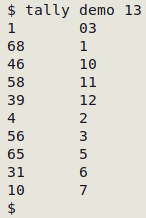
I've learned the hard way that data cleaning based on a pattern match is best done by careful attention to the address of the pattern. As a simple example, a "tally" of the "month" field (field 13) in the table "demo" shows that March has been represented by "03" in one record, instead of by "3":
It would be a mistake to globally replace "03" with "3" in the table, because there could be many other "03" strings in "demo" (e.g. something like "AU140362"):
sed 's/03/3/g' demo > demo1 #Wrong!!
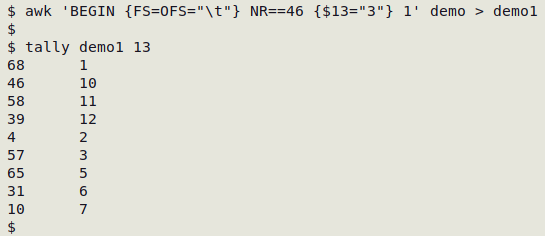
It would also be dangerous to identify the record number, then target just that record, for the same reason:

Identifying the record number (as above, with AWK) is a good idea if your next step is to modify that record in a text editor. (In Geany text editor, Ctrl + l [letter "ell"] and entering a line (record) number will take you to that record, flagged with an arrow.) On the command line, the safe way to do an insertion, deletion or replacement when cleaning data is to address both the record(s) and the field(s) for that action.
See also data item operations.
Duplicates
Exact, character-for-character duplicate records are easily found:
Display exact duplicate records
sort table | uniq -D
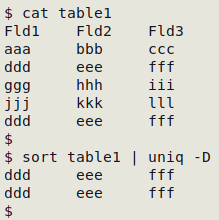
However, it's unlikely that you'll find exact, character-for-character duplicate records in a data table, especially if the table derives from a database which has added a unique ID string to each record. Removing that unique ID can reveal duplicate records:
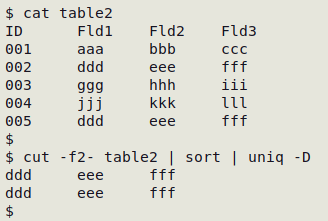
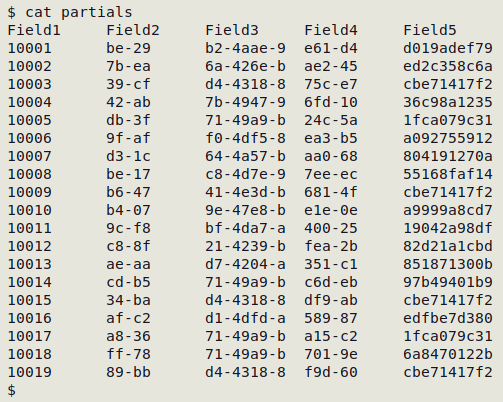
Partial duplicates
Each of the records in the table "partials" (screenshot below) is unique, even if the ID field (Field1) is ignored. It might be of interest, though, to check the table for partial duplicates, where only some fields are duplicated. The equivalent in a customer database might be records with the same address and phone number, but a differently spelled name.
The following command looks for records in "partials" with duplicate data items in fields 3 and 5. Although the "partials" table is processed twice by AWK, command execution is very fast. The follow-up sorting orders the duplicates by field 3 and by ID. For more information, see this BASHing data post.
awk -F"\t" 'FNR==NR {a[$3,$5]++; next} a[$3,$5]>1' partials partials | sort -t $'\t' -k3 -k1
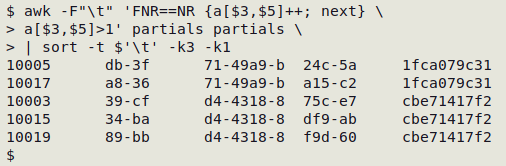
The "two-pass" AWK command can be adapted to any number of fields (see bottom of page). However, in a real-world case I had to modify the command because many of the records had blanks in the two fields being checked, and a blank is a duplicate of any other blank. I checked for blanks after noticing that the count of partial duplicates in fields 2 and 17 of "col1" was suspiciously large:

The modified command added the condition that field 2 was not blank. This reduced the number of partial-duplicate records to two. Apart from differences in the unique record ID (field 1) and the language of the institution name (field 16, "Národní muzeum" vs "National Museum of the Czech Republic"), the two records were identical:
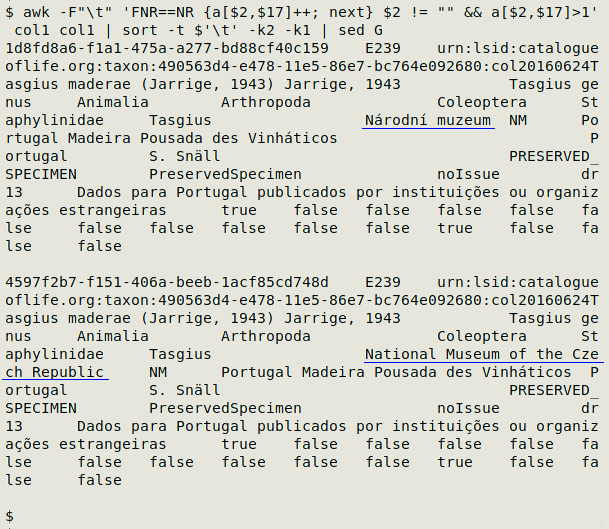
Partial duplicate searches can also be done where there are one or more unique ID fields, and you are looking for records that are duplicates apart from those unique ID entries. Rather than list all those non-unique-ID fields in the array index, it's easier to set the unique-ID entries to the same arbitary value, such as "1". In the second pass through the table, each whole record is first stored in a variable, and if the array value is greater than one, the variable is printed. For an example and more information, see this BASHing data post.
awk -F"\t" 'FNR==NR {[Set UI field(s) = 1; a[$0]++; next} \
{x=$0; [Set UI field(s) = 1]} a[$0]>1 {print x}' table table
An elegant one-pass variation of this command was suggested by Janis Papanagnou in 2023. The output is sets of partial duplicate records with each set separated by a blank line:
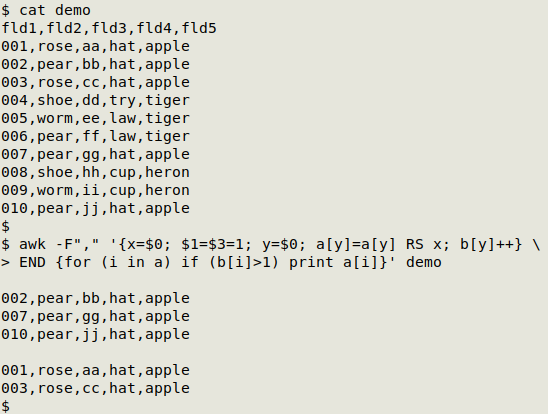
awk -F"\t" '{x=$0; [Set UI field(s) = 1]; y=$0; a[y]=a[y] RS x; b[y]++} END {for (i in a) if (b[i]>1) print a[i]}' table
In the screenshot below, the CSV "demo" has unique IDs in fields 1 and 3: