
For a full list of BASHing data blog posts, see the index page. ![]()
Partial duplicates
In the business world, duplicate records are only rarely true duplicates. More often they're multiple records for the same customer (for example) with spelling differences in the customer's name, or differences in the formatting of the customer's address.
Finding these "pseudoduplicates" can be difficult. OpenRefine might help, and there are many commercial services which offer deduplication at a price.
Another way to view pseudoduplicates is to see them as partial duplicates. Instead of looking for parts of a record that might be the same as parts of another, you could screen for combined parts of a record that are the same, but perhaps shouldn't be.
Here's an example. The 19 records in the tab-separated table below (called "file") are each unique, even if we ignore the record ID field (see screenshot).
| IDField1 | Field2 | Field3 | Field4 | Field5 |
| 10001 | be-29 | b2-4aae-9 | e61-d4 | d019adef79 |
| 10002 | 7b-ea | 6a-426e-b | ae2-45 | ed2c358c6a |
| 10003 | 39-cf | d4-4318-8 | 75c-e7 | cbe71417f2 |
| 10004 | 42-ab | 7b-4947-9 | 6fd-10 | 36c98a1235 |
| 10005 | db-3f | 71-49a9-b | 24c-5a | 1fca079c31 |
| 10006 | 9f-af | f0-4df5-8 | ea3-b5 | a092755912 |
| 10007 | d3-1c | 64-4a57-b | aa0-68 | 804191270a |
| 10008 | be-17 | c8-4d7e-9 | 7ee-ec | 55168faf14 |
| 10009 | b6-47 | 41-4e3d-b | 681-4f | cbe71417f2 |
| 10010 | b4-07 | 9e-47e8-b | e1e-0e | a9999a8cd7 |
| 10011 | 9c-f8 | bf-4da7-a | 400-25 | 19042a98df |
| 10012 | c8-8f | 21-4239-b | fea-2b | 82d21a1cbd |
| 10013 | ae-aa | d7-4204-a | 351-c1 | 851871300b |
| 10014 | cd-b5 | 71-49a9-b | c6d-eb | 97b49401b9 |
| 10015 | 34-ba | d4-4318-8 | df9-ab | cbe71417f2 |
| 10016 | af-c2 | d1-4dfd-a | 589-87 | edfbe7d380 |
| 10017 | a8-36 | 71-49a9-b | a15-c2 | 1fca079c31 |
| 10018 | ff-78 | 71-49a9-b | 701-9e | 6a8470122b |
| 10019 | 89-bb | d4-4318-8 | f9d-60 | cbe71417f2 |

I know, however, that there are partial duplicates lurking in this file, in the combined fields 3 and 5. The equivalent in a customer database might be "same address and phone number, but differently spelled name". To find these partial duplicates, I use one of two AWK commands. One reads the file twice and doesn't use much memory, and is suited to files of any size. The other command reads the file once; with big files it uses a lot of memory.
The two-pass command puts the field 3/field 5 combination in an array during the first pass through the file, and counts the number of occurrences of each combination. In the second pass, AWK matches the field 3/field 5 combination in the current line to the array, and prints that line if the array count is greater than 1:
awk -F"\t" 'FNR==NR {a[$3,$5]++; next} a[$3,$5]>1' file file
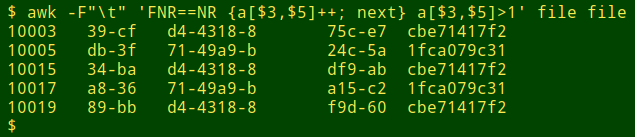
A follow-up sorting organises the output more neatly:
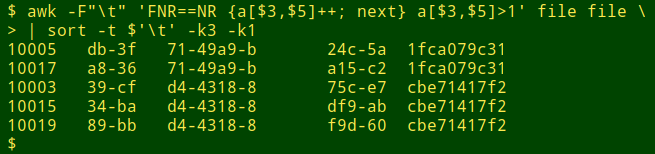
awk -F"\t" 'FNR==NR {a[$3,$5]++; next} a[$3,$5]>1' file file \
| sort -t $'\t' -k3 -k1
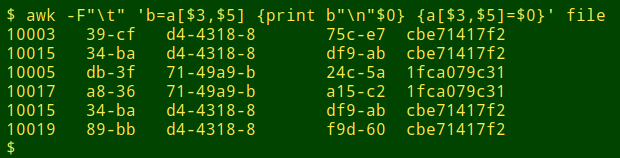
The one-pass AWK command puts every line into the array 'a', indexed by the field 3/field 5 combination. If the current line's fields 3 and 5 are already in 'a', the corresponding stored line is set equal to a variable 'b', and 'b' is printed followed by the line currently being checked. The next time there's a successful check of the array, 'b' is reset.
awk -F"\t" 'b=a[$3,$5] {print b"\n"$0} {a[$3,$5]=$0}' file
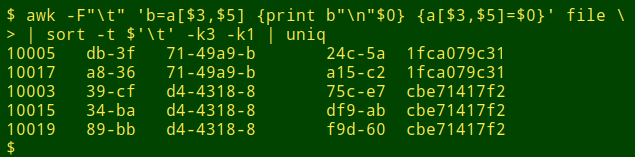
The output of the one-pass command needs uniquifying as well as sorting:
awk -F"\t" 'b=a[$3,$5] {print b"\n"$0} {a[$3,$5]=$0}' file \
| sort -t $'\t' -k3 -k1 | uniq
In a real-world case recently, I had to modify the two-pass command because many of the records had blanks in the two fields being checked, which made them "the same". I checked for blanks after noticing that the count of partial duplicates was suspiciously large:

The modification was to add another condition to the second part of the AWK command, namely that field 2 isn't blank:
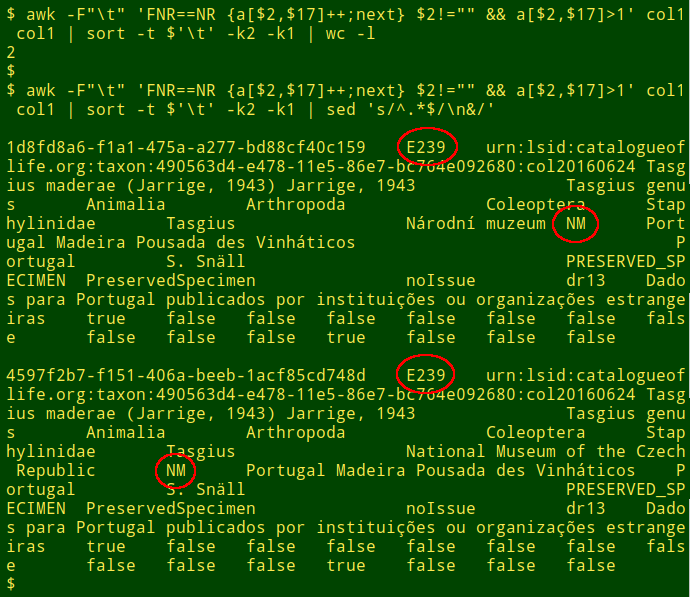
The two pseudoduplicated records have the same collection codes ("NM" in field 17) and catalog numbers ("E239" in field 2). Apart from different strings for the unique record ID (field 1) and the language of the institution name (field 16, "Národní muzeum" vs "National Museum of the Czech Republic"), the records are identical.
The 2-pass and 1-pass AWK commands make finding partial duplicates easy. The hard part of the job is deciding which fields to check!
To avoid having to write the two-pass command from scratch every time I use it, I've saved its skeleton in the function "coldupes", which uses the xclip utility:
coldupes() { echo -en "awk -F\"\\\t\" \x27FNR==NR {a[]++; next} \
a[]>1\x27 $1 $1 | sort -t \$\x27\\\t\x27 -k" | xclip; }
I enter "coldupes" and the filename in a terminal and press Enter. I then middle-click-paste at the next prompt to get the skeleton command, ready for adding the fields to check and the sort instructions:

Last update: 2018-07-14
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License