TSV This marker means that the recipe only works with tab-separated data tables.
Detecting gremlins
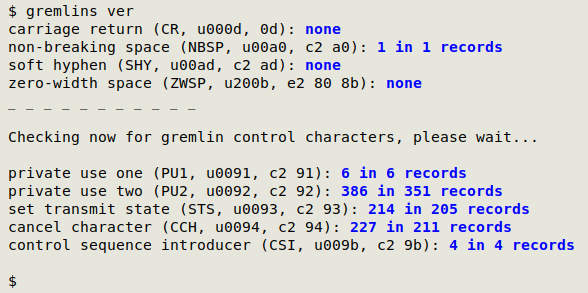
By "gremlins" I mean invisible characters other than whitespace, horizontal tab and linefeed. The following script (I call it "gremlins") is my gremlin detector and takes table name as its argument. The first part reports on carriage returns, non-breaking spaces, soft hyphens and zero-width spaces. The second part of the script looks for other unwanted control characters.
Script to detect and tally gremlin characters
(An earlier version of this script also looked for replacement characters, which aren't invisible. I now use the "rcwords" function for finding �)
#!/bin/bash
echo "u000d|carriage return (CR, u000d, 0d)
u00a0|non-breaking space (NBSP, u00a0, c2 a0)
u00ad|soft hyphen (SHY, u00ad, c2 ad)
u200b|zero-width space (ZWSP, u200b, e2 80 8b)" > /tmp/basegrem
echo "u0001|start of heading (SOH, u0001, 01)
u0002|start of text (STX, u0002, 02)
u0003|end of text (ETX, u0003, 03)
u0004|end of transmission (EOT, u0004, 04)
u0005|enquiry (ENQ, u0005, 05)
u0006|acknowledge (ACK, u0006, 06)
u0007|bell (BEL, u0007, 07)
u0008|backspace (BS, u0008, 08)
u000b|vertical tab (VT, u000b, 0b)
u000c|form feed (FF, u000c, 0c)
u000e|shift out (SO, u000e, 0e)
u000f|shift in (SI, u000f, 0f)
u0010|data link escape (DLE, u0010, 10)
u0011|device control 1 (DC1, u0011, 11)
u0012|device control 2 (DC2, u0012, 12)
u0013|device control 3 (DC3, u0013, 13)
u0014|device control 4IDC4 (u0014, 14, )
u0015|negative acknowledge (NAK, u0015, 15)
u0016|synchronous idle (SYN, u0016, 16)
u0017|end of transmission block (ETB, u0017, 17)
u0018|cancel (CAN, u0018, 18)
u0019|end of medium (EM, u0019, 19)
u001a|substitute (SUB, u001a, 1a)
u001b|escape (ESC, u001b, 1b)
u001c|file separator (FS, u001c, 1c)
u001d|group separator (GS, u001d, 1d)
u001e|record separator (RS, u001e, 1e)
u001f|unit separator (US, u001f, 1f)
u007f|delete (DEL, u007f, 7f)
u0080|padding character (PAD, u0080, c2 80)
u0081|high octet preset (HOP, u0081, c2 81)
u0082|break permitted here (BPH, u0082, c2 82)
u0083|no break here (NBH, u0083, c2 83)
u0084|index (IND, u0084, c2 84)
u0085|next line (NEL, u0085, c2 85)
u0086|start of selected area (SSA, u0086, c2 86)
u0087|end of selected area (ESA, u0087, c2 87)
u0088|horizontal tab (HTS, u0088, c2 88)
u0089|horizontal tab with justification (HTJ, u0089, c2 89)
u008a|line tabulation set (VTS, u008a, c2 8a)
u008b|partial line down (PLD, u008b, c2 8b)
u008c|partial line up (PLC, u008c, c2 8c)
u008d|reverse index (RI, u008d, c2 8d)
u008e|single shift two (SS2, u008e, c2 8e)
u008f|single shift three (SS3, u008f, c2 8f)
u0090|device control string (DCS, u0090, c2 90)
u0091|private use one (PU1, u0091, c2 91)
u0092|private use two (PU2, u0092, c2 92)
u0093|set transmit state (STS, u0093, c2 93)
u0094|cancel character (CCH, u0094, c2 94)
u0095|message waiting (MW, u0095, c2 95)
u0096|start of protected area (SPA, u0096, c2 96)
u0097|end of protected area (EPA, u0097, c2 97)
u0098|start of string (SOS, u0098, c2 98)
u0099|single graphic character introducer (SGCI, u0099, c2 99)
u009a|single character introducer (SCI, u009a, c2 9a)
u009b|control sequence introducer (CSI, u009b, c2 9b)
u009c|string terminator (ST, u009c, c2 9c)
u009d|operating system command (OSC, u009d, c2 9d)
u009e|privacy message (PM, u009e, c2 9e)
u009f|application program command (APC, u009f, c2 9f)" > /tmp/othergrem
grep -P '\x{000d}|\x{00a0}|\x{00ad}|\x{200b}' "$1" > base
grep -P "[\x01-\x08\x0b\x0c\x0e-\x19\x1a-\x1f\x7f\x80-\x9f]" "$1" > other
while read line; do awk -v STR="$line" -v CHAR="$(printf "\\$line")" 'FNR==NR {a[$1]=$2; next} $0 ~ CHAR {cnt++; n+=gsub(CHAR,"")} END {print a[STR]": "(n==0 ? "\x1b[1;34mnone\x1b[0m" : "\x1b[1;34m"n" in "cnt" records\x1b[0m")}' FS="|" /tmp/basegrem base; done <<<"$(cut -f1 -d"|" /tmp/basegrem)"
printf "_ _ _ _ _ _ _ _ _ _ _ \n"
printf "\nChecking now for gremlin control characters, please wait..."
echo
awk '$/\x00/ {cnt++; n+=gsub(/\x00/,"")} END {if (n>0) print "null (NUL, u0000, x00):\x1b[1;34m "n" in "cnt" records\x1b[0m"}' "$1" > /tmp/others
while read line; do awk -v STR="$line" -v CHAR="$(printf "\\$line")" 'FNR==NR {a[$1]=$2; next} $0 ~ CHAR {cnt++; n+=gsub(CHAR,"")} END {if (n>0) print a[STR]": \x1b[1;34m"n" in "cnt" records\x1b[0m"}' FS="|" /tmp/othergrem other; done <<<"$(cut -f1 -d"|" /tmp/othergrem)" >> /tmp/others
echo
if [ -s /tmp/others ]; then
cat /tmp/others
else
printf "No NULs or gremlin control characters found\n\n"
fi
echo
rm /tmp/basegrem /tmp/othergrem /tmp/others base other
exit 0
The "gremlins" script at work on the data table "ver":
Visualising gremlins
The "gremfinder" script (below) looks for individual gremlin characters identified by the "gremlins" script, based on their "core" hex value (main byte). It automatically adds "c2" to the "core" hex value where needed in UTF-8 encoding, and locates gremlins by field. The script takes as its two arguments the name of the data table and the "core" hex value. It generates a plain-text, tab-separated table with record number, field number and data item (with the gremlin); the table is named "[selected hex value]-list-table".
If wanted, the script then prints a uniquified list of data items in each field, with the invisible gremlin replaced by {HERE}. The printing is done from less with two options: -R to allow ANSI colors, and -X to allow the print to persist on screen (return to prompt by pressing "q").
Interactive script to extract data items containing a selected gremlin character (hex version) TSV
#!/bin/bash
redden=$(printf "\033[31;1m")
reset=$(printf "\033[0m")
if ((128 > $(printf "%d" "0x$2"))); then
char=$(printf "\x$2")
else
char=$(printf "\xc2\x$2")
fi
awk -F"\t" -v grem="$char" '$0 ~ grem {for (i=1;i<=NF;i++) {if ($i ~ grem) {print NR FS i FS $i}}}' "$1" | sort -t $'\t' -nk2 -nk1 > "$2"-list-"$1"
echo
echo "Table \"$1\" has \"$2\"-containing words in the following field(s):"
cut -f2- "$2"-list-"$1" | sort | uniq -c | sed 's/[ ]*//;s/[ ]/\t/' | awk -F"\t" '{print "\tfield "$2" in "$1" records"}'
echo
read -p "Show uniquified results with less? (y/n)" foo
echo
if [ "$foo" == "n" ]; then
exit 0
else
cut -f2- "$2"-list-"$1" | sort -n | uniq | sed "s/$char/${redden}{HERE}${reset}/g" | less -RX
fi
exit 0
In the screenshot below, "gremfinder" is looking for the HTJ (hex c2 89) gremlin in "oc1":

The script "gremfinderu" is the same as "gremfinder" but looks for gremlins using their Unicode code point (unnnn) instead of the "core" hex value. The screenshot shows "gremfinderu" locating "u008d" characters in the UTF-8 file "oc2":
Interactive script to extract data items containing a selected gremlin character (Unicode version) TSV
#!/bin/bash
redden=$(printf "\033[31;1m")
reset=$(printf "\033[0m")
char=$(printf "\\$2")
awk -F"\t" -v grem="$char" '$0 ~ grem {for (i=1;i<=NF;i++) {if ($i ~ grem) {print NR FS i FS $i}}}' "$1" | sort -t $'\t' -nk2 -nk1 > "$2"-list-"$1"
echo
echo "Table \"$1\" has \"$2\"-containing words in the following field(s):"
cut -f2- "$2"-list-"$1" | sort | uniq -c | sed 's/[ ]*//;s/[ ]/\t/' | awk -F"\t" '{print "\tfield "$2" in "$1" records"}'
echo
read -p "Show uniquified results with less? (y/n)" foo
echo
if [ "$foo" == "n" ]; then
exit 0
else
cut -f2- "$2"-list-"$1" | sort -n | uniq | sed "s/$char/${redden}{HERE}${reset}/g" | less -RX
fi
exit 0

An alternative way to locate occasional (not numerous) gremlins is with the "heremark" function. It finds gremlins by their Unicode code point (unnnn) as the second argument and prints the line number, the field number and the full data item with the gremlin replaced by {HERE}. If less is used to page the "heremark" results, it should be run with the -R option to allow ANSI colors.
Function to extract and locate data items with a selected gremlin character (Unicode version) TSV
heremark() { char=$(printf "\\$2"); awk -F"\t" -v find="$char" '$0 ~ find {for (i=1;i<=NF;i++) if ($i ~ find) {gsub(find,"\33[31;1m{HERE}\33[0m",$i); print "line "NR", field "i":\n"$i}}' "$1"; }
Below, "heremark" lists the data items in "ver" with the private use 1 (PU1) control character:

Removing gremlins
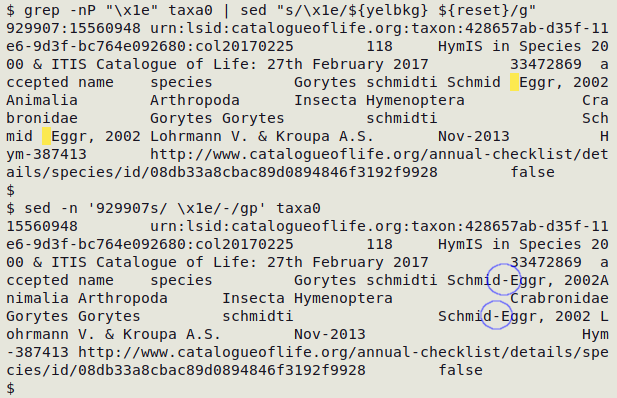
Gremlins can be destroyed or replaced globally with tr or sed using the gremlin hex values. It's better to check first where the gremlins are, as described in the preceding section. In the real-world example below, a space and a record separator (RS; hex 1e) have taken the place of the hyphen in the name 'Schmid-Eggr' on line 929907 of the data table "taxa0". Just deleting the gremlin would not correct the text. Here sed replaces the space+RS with a hyphen in the relevant record.