|
On this page:
|
On the Data tables 1 page:
|
|
On the Data tables 2 page:
|
On the Data tables 4 page:
|
Tidy data tables
Data cleaning doesn't always start with tidy, well-organised data. Below are some of the problems you may find before cleaning that are not covered elsewhere in this cookbook. (See also inherited spreadsheet problems.). This page is based on a BASHing data blog post.
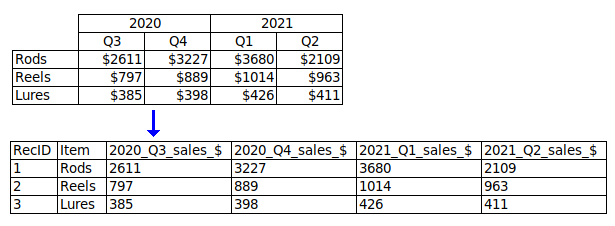
Two or more separate tables per table. If there are multiple, similar tables in a single table grid, ask the data provider if they can be combined into a single table, otherwise split them into separate files.
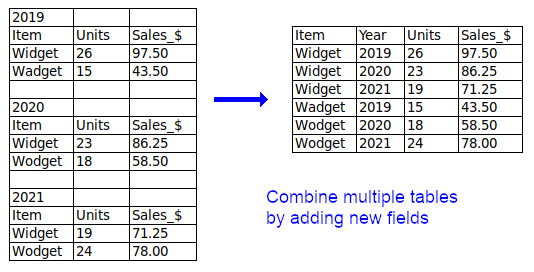
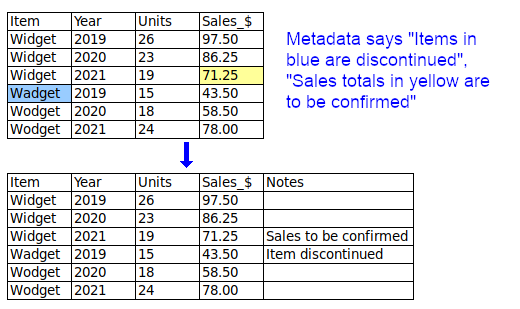
Metadata. A data table prepared for processing should not contain caption lines or explanatory information lines. If possible, footnotes and comments should be put in a new field. All other metadata belongs in the filename or in a separate file accompanying the table.

Font or colour mean something. The data may arrive "decorated" in a spreadsheet. When the table is converted to plain text for processing, any font or colour differences are lost, and with them their meaning. The "font or colour" information should be put in a new, separate field or fields.
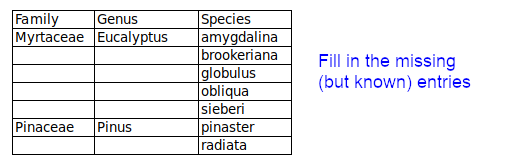
Known entries are left out. Some data items may be blanked in a spreadsheet, as shown below, to "visually organise" lists. To avoid incomplete records in data processing, any missing-but-known entries should be filled in.
Data not sufficiently atomised The more fields you can split a data item into, the better. In a table designed for human eyes, you might keep the table narrow by packing different data items into single fields. For example, you might have a "Name" field instead of "Title", "First_name" and "Last_name" fields, to save space. When processing data as plain text, it doesn't matter how wide the table is. By splitting data items you make it easier to extract information and to check for inconsistencies and errors. (See also domain schizophrenia.)
Abbreviations in data items. Abbreviations can be incomprehensible or ambiguous. There's always enough room in a digital data table to expand abbreviations. Ask the data provider if your suggested expansions or additions are acceptable.
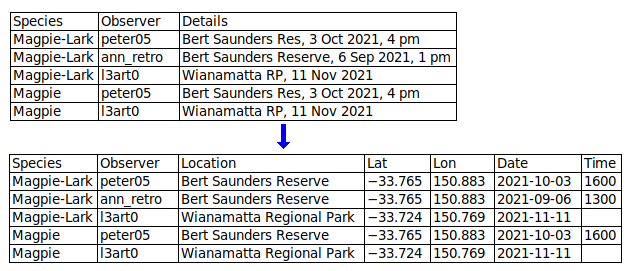
Field names not in a single line (the header).
Field names not well formatted. Spaces and punctuation (apostrophes, quotes, question marks, commas etc) should be avoided in field names. Good replacements for spaces are underscores, hyphens and merges, e.g. "First_name", "First-name" and "FirstName". Abbreviations should also be avoided; "AbsTemp_K" is better than "AT_K", and "AbsoluteTemperature_K" is better still. In serially numbered fields, the number should go last, e.g. "address1" and "address2", not "1st_address" and "2nd_address".
Field names don't clearly explain their content. "Date", "Price" and "Area" are understandable but incomplete. Date of what? (e.g. "Date_purchased"). What kind of price? (e.g. "Price_retail"). What units for area? (e.g. "Area_ha"). Ambiguity may be another problem: does "GuestNo" mean total number of guests, or a code number for individual guests?
No unique ID for each record (where appropriate). The unique ID can be as simple as a serial number: 1,2,3...