
For a full list of BASHing data blog posts see the index page. ![]()
The Incrementing Fill-Down Error
WGS84 (also written WGS 84) is short for World Geodetic System 1984. It's the spatial standard used by most GPS receivers to calculate their position on the Earth's surface.
WGS84 is maintained by the US Department of Defense and gets periodic updates. The updates are also "WGS84". They're not called WGS85, or WGS86, or WGS87. Nevertheless, when auditing data tables with a geodetic datum field I sometimes find entries like WGS85, WGS86 and WGS87. One table had all the numbers up to WGS123. I call these Incrementing Fill-Down Errors, or IFDEs for short, and they probably originated in a spreadsheet. The spreadsheet user wanted to copy "WGS84" down a column of cells, but somehow the copying turned into incrementing. The order of the cells was later lost when the records were sorted on another field.
Another IFDE I saw recently, in a scientific name field, looked something like this after sorting:
Carabus auratus Linnaeus, 1761
Carabus auratus Linnaeus, 1762
Carabus auratus Linnaeus, 1763
Carabus auratus Linnaeus, 1764
Carabus auratus Linnaeus, 1765
Carabus auratus Linnaeus, 1766
Carabus auratus Linnaeus, 1767
Carabus auratus Linnaeus, 1768
The beetle species Carabus auratus was first named and described by Carl Linnaeus in 1761, not in 1762, 1763 etc. I suspect this IFDE also originated in a spreadsheet, but how did the data compiler get the year to increment?
IFDEs are serious data errors. I can usually spot potential IFDEs by eye after doing a tally on a field, but this post describes one way to code an IFDE detector.
Here's the demonstration file, "test":
meat73
pail225
zipper3
cactus61
competition05
25pollution487
winter
pump1763
rest
winter
pump1763
snakes25
rest
snakes24
harmony
pet91
zipper9
winter
harmony
pail225
snakes26
zipper9
cactus58
zipper3
cactus61
26pollution487
12meat73
pail225
pump1763
harmony
competition05
pet91
competition05
cactus61
pet91
rest
cactus58
12meat73
24pollution487
cactus58
zipper3
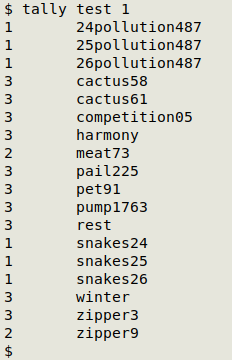
A tally shows there's a possible IFDE in the snakes:
OK, as a first step I'll sort -V and uniquify the file:
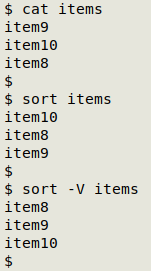
I use sort with the -V option to ensure the sort sees the numbers as "version numbers" rather than literal characters. That won't matter in the "test" case but it might in other files:
The next step is to split each string into the numbers at the end (the "tail") and everything else (the "head "). I use AWK to do this:
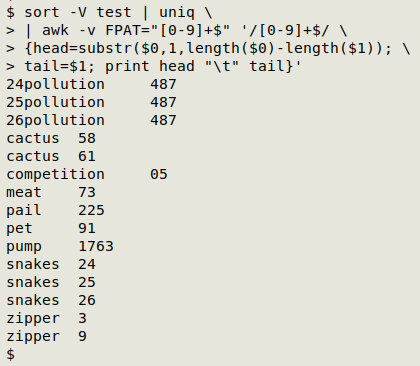
AWK is here told with the FPAT variable that fields are defined by the regex pattern [0-9]+$, which means "1 or more digits at the end of the string". Each string will therefore have just one field, $1, namely the tail. The same regex is used to select just the strings that have, in fact, some numbers at their ends (/[0-9]+$/). To get the head I use AWK's substr function, operating on the entire string ($0), starting with the first character (1) and finishing the substring with the character just before the tail (length($0)-length($1)).
To find the IFDE I replace the print statement in the AWK command with something more complicated:
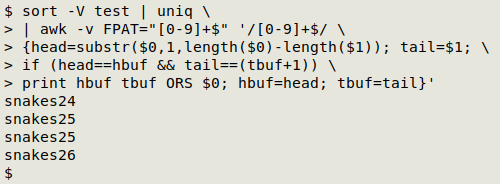
AWK starts processing the sorted and uniquified "test" with the first line. After defining "head" and "tail" in that first line, AWK moves on to an if condition which mentions "hbuf" and "tbuf". Since these haven't been defined yet, no action is taken. At the end of the command, "hbuf" is defined as the current line's "head", and "tbuf" as the current line's "tail".
Beginning with the second line, AWK can work with the if statement. It says: If "head" in the current line is the same as "head" in the previous line, and if "tail" in the current line is "tail" in the previous line plus 1, then print the previous line's "head" and "tail" (concatenated), followed by a newline (ORS = the default record separator, a newline), followed by the current line.
The first time this condition is met is on the line "snakes25", and AWK prints "snakes24" followed by "snakes25". This condition is also met by the "snakes26" line, so AWK again prints the previous line followed by the current line, this time "snakes25" followed by "snakes26". No more lines satisfy the if condition, so no more lines are printed.
To get rid of the duplicated line "snakes25" in the IFDE I pipe the AWK output to sort -V and uniq. It's possible to get rid of duplicates inside the AWK command, but only by adding more conditions and making the command way more complicated. sort -V | uniq is simpler:
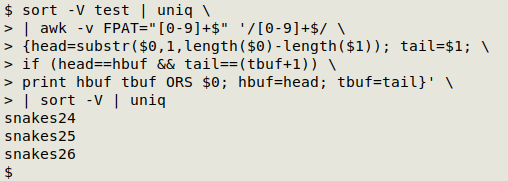
sort -V test | uniq | awk -v FPAT="[0-9]+$" '/[0-9]+$/ {head=substr($0,1,length($0)-length($1)); tail=$1; if (head==hbuf && tail==(tbuf+1)) print hbuf tbuf ORS $0; hbuf=head; tbuf=tail}' | sort -V | uniq
I saved the IFDE detecting code in the function "ifder". Here's what "ifder" found in field 16 (scientific name) of the 7606-record TSV "oc":
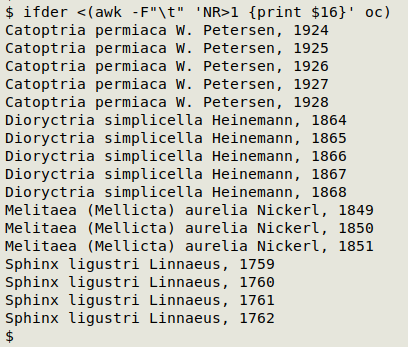
Sigh. At least "oc" had only "WGS84" in its geodetic datum field.
Update. Bernie Hane writes that he was able to reproduce the "Carabus auratus Linnaeus, 1761" IFDE in Microsoft Excel, and I did the same in LibreOffice Calc by dragging down the little black square in the lower right corner of the top cell:
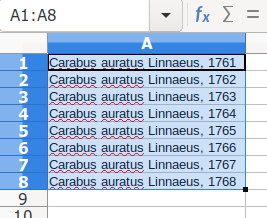
This is Calc's default behaviour. To get Calc to simply copy down the top cell's contents, press Ctrl when dragging the little black square.
Last update: 2021-05-28
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License