
For a list of BASHing data 2 blog posts see the index page. ![]()
Data noise
All the datasets I audit are UTF-8 encoded and tab-separated text files. They contain letters, numbers, punctuation and spaces, and they're correctly separated into records and fields. They're what I call "tidy", but many of them still aren't "clean" because they contain unnecessary data noise.
Here are the noisy elements I see regularly:
- unneeded carriage returns at line ends
- blank fields at the ends of records
- records containing only empty data items
- spaces that aren't really spaces
- unneeded quotes around data items
I also see, or rather detect, the invisible byte order mark U+FEFF at the beginning of a file. A BOM in a UTF-8 dataset isn't needed (UTF-8 byte order doesn't vary), but the BOM also won't affect my processing, so I ignore it. The other five kinds of data noise bugger up what I do and I need to de-noise.
Carriage returns in CRLF line endings. These are bad juju and A Data Cleaner's Cookbook has advice on detecting CRLF line endings and converting them to plain ones.
Blank fields at the ends of all records. These contain no data but will show up in field-by-field processing, so they need to be killed. The empties script will remove them for processing purposes, but they can also be removed in advance. One way is to count the number of trailing tabs in the header line, then delete that number of tabs from the end of all lines:
foo=$(awk -F"[^\t]" 'NR==1 {print length($NF)}' [file]
sed -E "s/\t{${foo}}$//" [file]
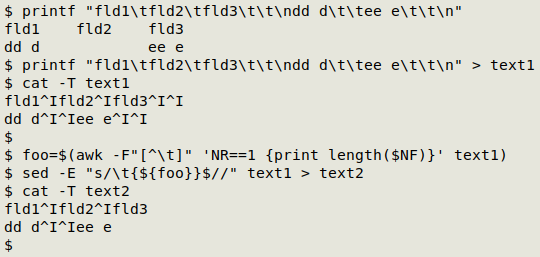
For an explanation of what AWK and sed are doing here, see this BASHing data post from 2020.
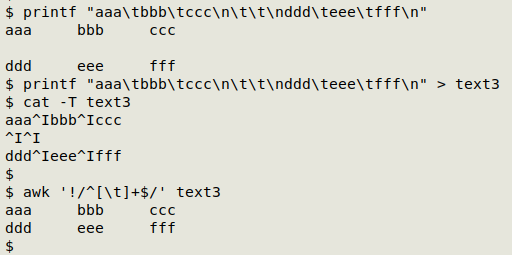
Records containing only empty data items. These records aren't the same as completely blank ones, which can be deleted (for example) with grep . or awk NF. The noisy records contain only tab field separators and can be filtered out with AWK:
awk '!/^[\t]+$/' [file]
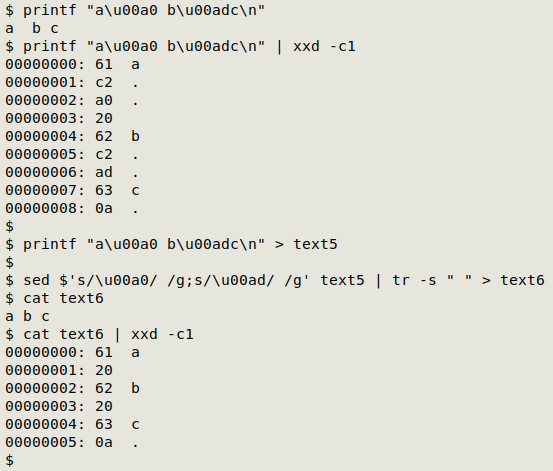
Spaces that aren't really spaces. These are the formatting characters no-break space (NBSP; U+00A0) and soft hyphen (SHY; U+00AD). They look like spaces in the terminal but they don't behave like spaces and will cause data-processing errors. NBSPs and SHYs are detected by the gremlins script; see also this NBSP visualiser. The safest way to get rid of them, in my experience, is to replace them with plain spaces using sed, then follow up with a tr space squeeze to remove duplicate spaces:
sed $'s/\u00a0/ /g;s/\u00ad/ /g' [file] | tr -s " "
Unneeded quotes around data items. In an extreme case of formatting silliness, the Atlas of Living Australia makes available tab-separated datasets with every single data item surrounded by quotes. (For more, see here.) More commonly I see unnecessary data-item quoting in TSV datasets converted from CSVs.
If I know for certain that none of the data items in the dataset should contain quotes, I can delete all quotes globally with tr -d "\"". Some data items might contain quotes legitimately, however, as in "Woolnorth" property and 41°26'38" S. I can delete any data-item-bracketing quotes with
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /"[^"]*"/) {sub(/^"/,"",$i);sub(/"$/,"",$i)}} 1' [file]

and then do a search for residual quotes to see if they're legitimately needed. Another helpful procedure is to reduce multiple quotes with a tr squeeze:
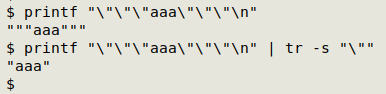
Quote noise makes data auditing difficult and I wish I didn't see it so often!
Next post:
2025-08-15 Square root days, prime years and maximum-factor years
Last update: 2025-08-08
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License