
For a full list of BASHing data blog posts see the index page. ![]()
Detecting truncations: another sometimes successful method
I occasionally find truncated strings in a data audit. These usually appear when a data item has been entered in a free-text field with a character limit. For example, this string with 77 characters
A fool thinks himself to be wise, but a wise man knows himself to be a fool
looks like this when entered in a 75-character field:
A fool thinks himself to be wise, but a wise man knows himself to be a fo
Detecting truncations programmatically is difficult and not always successful. I usually try one or all of these three methods for a selected field:
- Look for bulges in the frequency distribution of data item lengths, especially at 50, 100, 200 and 255 characters
- Look for unmatched braces within data items
- Look for data items ending in punctuation, a trailing space or both
I then inspect any suspect items and try to decide whether something has been chopped off the right-hand end of the string. That's not always a straightforward decision, and I generally refer the suspects to the data compiler as queried entries.
I've been tinkering with a fourth method, for datasets compiled from several different sources with overlapping content. These datasets might contain both a truncated and a full version of the same data item. Here's a simplified example:
This sentence contains five words
This sentence contains just six words
This sentence contains just six wo
This sentence contains five words
This sentence contains just six words
This sentence contains just six wo
This sentence contains five words
This sentence contains just six words
This sentence contains just six wo
To tally the truncated and full versions, I can use this command:
awk 'FNR==NR {a[$0]=$0; next} {for (i in a) if ($0 ~ a[i] && length($0) > length(a[i])) print a[i] "\n" $0}' demo9 demo9 | sort | uniq -c
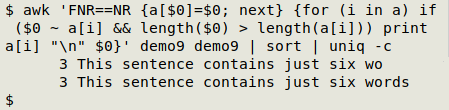
The AWK command makes two passes through "demo9". In the first pass, all entries are put in to an array "a" with the entry as both index string and value string.
In the second pass, AWK goes through the array's index, unique item by unique item, and checks to see whether the current line matches the array string. If it does, and if the current line is longer than the array string, then AWK prints the array string, a newline and the current line.
The AWK output is then sort and tallied with uniq -c.
In a data audit I use this command on individual fields rather than on whole files.
Asking AWK to check every line against every line clearly takes a lot of time. To get some idea of the time requirement, I repeated the nine lines in the "demo9" file as 900-, 9000-, 90000- and 900000-line versions. The times were (6 core Intel Core i5-9500T, 8GB RAM):
- demo9 = 0.01s
- demo900 = 0.06s
- demo9000 = 0.53s
- demo90000 = 5.22s
- demo900000 = 51.34s
Well, five seconds isn't too long for 90000 lines, but waiting for AWK to process longer lists of data items gets pretty tedious. To cut the time I can uniquify the items in the list. In the "demo" series, of course, that would reduce every list to just the three unique lines.
In any event, the results of this fourth method need to be inspected and queried. Was there truncation in the first data item below, or is it a different habitat description?
Old-growth Nothofagus with Atherosperma, Dicksonia #exactly 50 characters
Old-growth Nothofagus with Atherosperma, Dicksonia, occasional Anodopetalum
Did I mention that detecting truncation is difficult?
Last update: 2021-12-15
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License