
For a list of BASHing data 2 blog posts see the index page. ![]()
zet for sets
Continuing the "z" theme from last week's BASHing data 2 post, this one demonstrates the zet utility for doing set operations on text files.
zet was written in Rust by developer "yarrow". It's easily installed with cargo install zet, but first make sure your Rust libraries are up to date. To show zet at work I'll use the following three semicolon-separated tables:
tabA:
Species;Latitude;Longitude;Date
Lissodesmus adrianae;-41.2261;147.8831;2005-01-17
Lissodesmus alisonae;-41.6328;146.8406;1992-03-05
Lissodesmus hamatus;-42.7069;147.8414;1988-06-26
Lissodesmus latus;-41.1136;144.9850;1991-11-13
Lissodesmus hamatus;-41.0564;147.6606;1993-03-18
Lissodesmus alisonae;-41.0581;147.1633;1992-02-20
tabB:
Species;Latitude;Longitude;Date
Lissodesmus hamatus;-41.4483;147.4264;1994-08-11
Lissodesmus bashfordi;-42.9344;146.9650;2003-11-29
Lissodesmus perporosus;-41.0750;145.7681;2002-10-12
Lissodesmus clivulus;-41.3117;144.7433;1981-04-18
Lissodesmus adrianae;-41.1425;147.7258;1993-03-17
Lissodesmus latus;-41.1136;144.9850;1991-11-13
tabC:
Species;Latitude;Longitude;Date
Lissodesmus latus;-41.1136;144.9850;1991-11-13
Lissodesmus latus;-41.3356;145.6306;1979-01-22
Lissodesmus hamatus;-41.8544;148.2014;1988-07-20
Lissodesmus hamatus;-40.9089;148.1886;1992-11-25
Lissodesmus perporosus;-41.0750;145.7681;2002-10-12
Lissodesmus devexus;-41.2286;147.8892;1990-08-27
I often need to combine tables like these without changing the order of the lines, but with deletion of any duplicate lines. A simple CLI method would be to stack the files with cat, then remove duplicate lines with AWK (preserving the line order):
cat tabA tabB tabC | awk '!a[$0]++'
The zet union option does the job with a single command:
zet union tabA tabB tabC
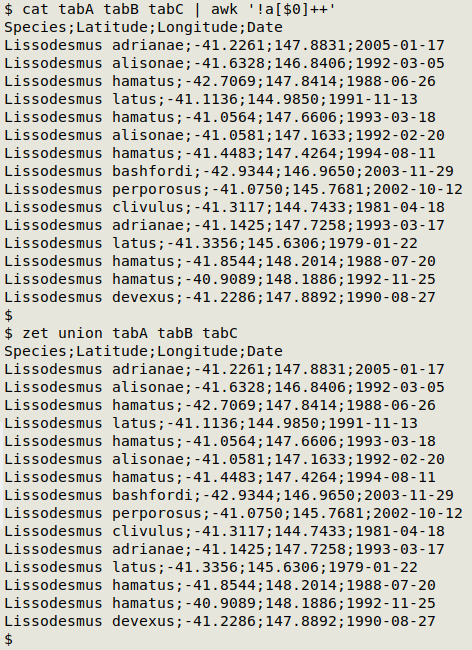
What lines are shared by combinations of the tables? I could use comm, but because that's limited to intersecting two files, I'd need to do multiple commands for all three tables, while zet can do intersections with more than two files as arguments:
zet intersect tabA tabB
zet intersect tabA tabC
zet intersect tabB tabC
zet intersect tabA tabB tabC
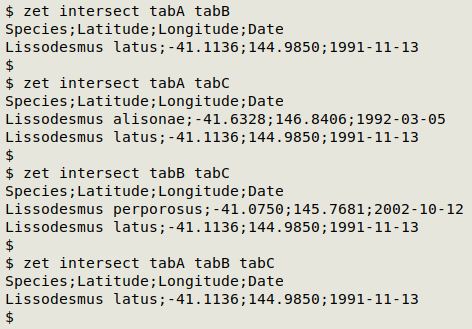
How about the lines that appear in tabA, but not in tabB or tabC?
zet diff tabA tabB tabC
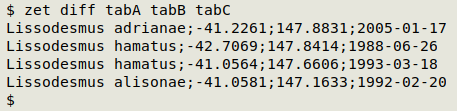
Lines that appear more than once in the three files taken as a group, plus a count of those lines?
zet multiple tabA tabB tabC
zet -c multiple tabA tabB tabC
Lines that appear exactly once in the three files taken as a group? (Like sort -u, but preserving the line order)
zet single tabA tabB tabC
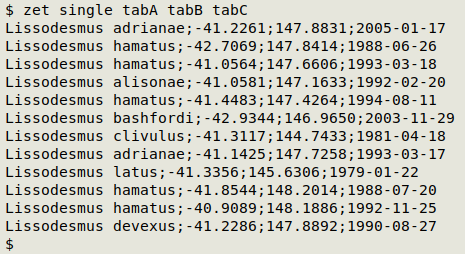
There are a couple of other zet options but the above are the basics for set-type operations. What I really like about zet is that the same simple syntax can be used for all these operations, and that line order is preserved.
Next post:
2025-08-08 Data noise
Last update: 2025-08-01
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License