
For a list of BASHing data 2 blog posts see the index page. ![]()
GNU sed's handy -z option
In 2012 the GNU sed developers added a new option, -z. Its effect is to replace newlines in the stream fed to sed with NULL characters.
That might sound a little ho-hum, so I'll rephrase it this way: the -z option converts the input into a single long line while sed works on it. This means you can take advantage of sed's "numbered occurrence" feature to do replacements on whole files.
To demonstrate I'll use the following block of text, called "demo":
a0116c89a169476ca747
5231e2759e7e4fb8b22e
e845cc07ec6a49a16598
a61589a16309426a9475
32d48b8fce0c45b285a5
3c47072fb9a16db38f5f
412f50fd33654096b79a
1629c5b673a542e082d8
fbe01d0a39a168168c03
01ff5040783749d9a0a1
Buried in this block are five occurrences of the string "9a16". Suppose I want to find just the third occurrence of "9a16" and replace it with "ABBA". I can't just do sed 's/9a16/ABBA/3' demo, because sed is a line-based editor, and there's no line in "demo" with 3 instances of "9a16". Instead I do
sed -z 's/9a16/ABBA/3' demo
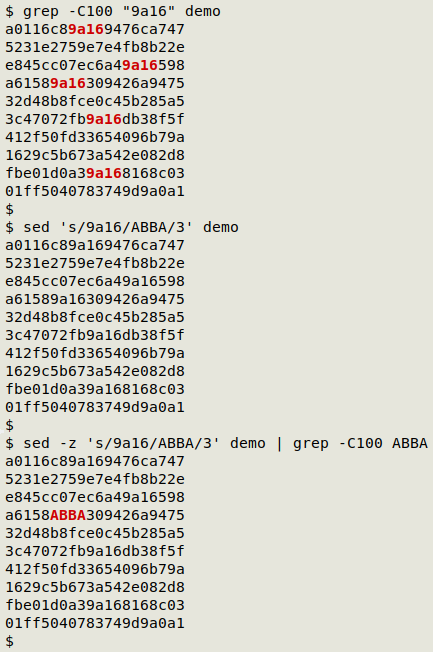
grep -C [some big number] is a hack-y way to find lines with targets and also show the rest of the lines. The -C [n] option prints "n" lines either side of a match, and choosing "n" bigger than the number of lines in the file means the whole file will be printed.
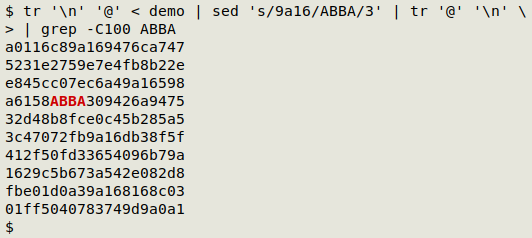
There are at least two other ways to do the replacement. The first is to convert "demo" into a single long line with a shell tool like tr, then use the simpler sed command, then restore the line:
tr '\n' '@' < demo | sed 's/9a16/ABBA/3' | tr '@' '\n'
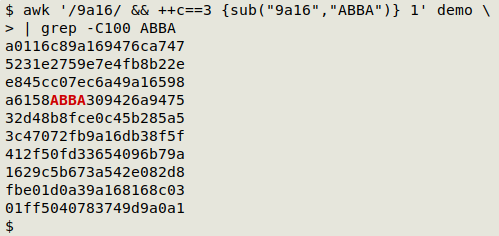
A second method is to use AWK to count occurrences of "9a16" and substitute the third occurrence:
awk '/9a16/ && ++c==3 {sub("9a16","ABBA")} 1' demo
The -z option can also be used to find the "nth" and all succeeding occurrences, by combining "n" with "g":
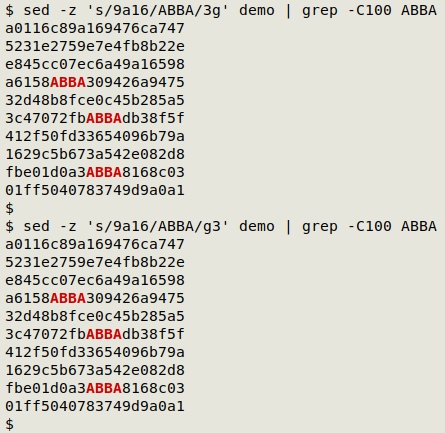
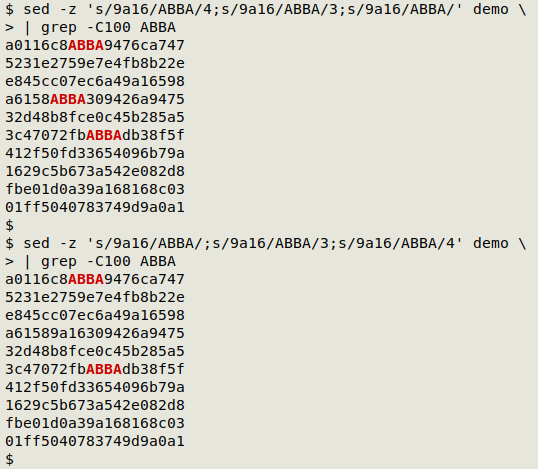
What if you want to replace the first, third and fourth occurrence of "9a16"? Unfortunately sed can't do that in a single command, because you can only use one number at a time with the "numbered occurrence" syntax. Here I use 3 separate commands, and note that I've run the numbering backwards to get the replacements done one after the other in sed's pattern space. If I put the commands in 1, 3, 4 order, the replacement numbering will be off, as shown in the screenshot.
sed -z 's/9a16/ABBA/4;s/9a16/ABBA/3;s/9a16/ABBA/' demo
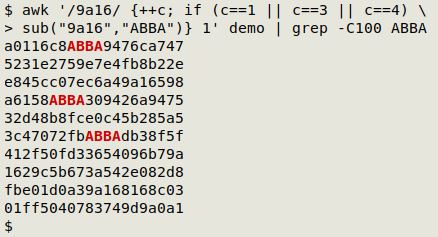
The AWK equivalent is
awk '/9a16/ {++c; if (c==1 || c==3 || c==4) sub("9a16","ABBA")} 1' demo
Next post:
2025-08-01 zet for sets
Last update: 2025-07-25
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License