
For a list of BASHing data 2 blog posts see the index page. ![]()
Anatomy of a data analysis
This post explains how and why I picked a particular way of summarising some data. The file "occurrence.csv" had 5,526,577 records plus a header line and was divided into 74 fields, one of which divided the dataset into 4 different categories of records. What I wanted to do was count the number of records that had no visible characters at all (blank entries) in certain selected fields for each of those 4 categories.
Preliminaries. The first job was to get the file out of the awful, horrible CSV format into TSV. A grep check showed that the file had lots of tabs within fields, so I replaced each tab with a single space using sed. The modified CSV was then converted to a TSV using csvformat (from csvkit) and I did an AWK check to ensure that every record had the same number of tab-separated fields:

The field dividing the records into 4 categories was field 6 (tally function used here). To simplify the results I wanted to convert the string "BMNH(E)" to "ENT", but because that string also appeared in fields before field 6, I did a field-targeted AWK replacement rather than a "replace first occurrence" one with sed:

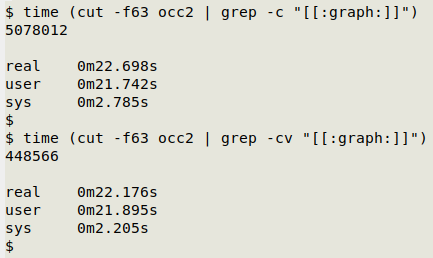
Finding blanks. My "preliminaries" experience was that some commands took a fair bit of time to execute on this big file ("occ2" was 11.2 GB), so to get reasonably quick results I turned to a speed wizard, grep. Would it make a difference, though, if I counted entries without visible characters, or for entries with visible characters, which I could then subtract from the entries total? A trial on a single field showed that the time difference was minimal, and I chose to count "without" directly:
Getting field numbers. My plan was to look for blanks in 3 sets of fields: 11 "what" fields, 12 "where" fields and 23 "what" and "where" fields combined.

To find the field number strings for cut -f[field numbers] commands I used the fields function:
what="5,20,23,28,34,38,56,58,63,66,68"
where="7,9,12,13,29,36,37,45,67,71-73"
both="5,20,23,28,34,38,56,58,63,66,68,7,9,12,13,29,36,37,45,67,71-73"
I could have gotten those numbers with code, but it was quicker to just read them off the fields output in my terminal when building the "what", "where" and "both" variables at the next 3 prompts.
Getting blank counts by category. Here I looped through 2 BASH arrays, one for the "what/where/both" and one for the 4 categories (explanation below). The series of commands shown below generated the desired table in about 1 minute:
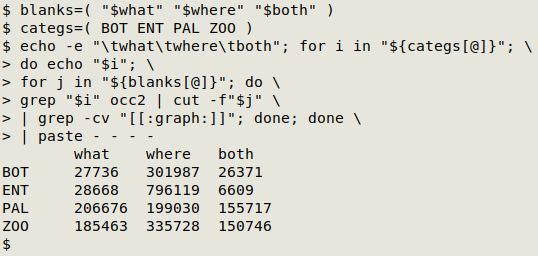
The "blanks" array stores the "what", "where" and "both" variables. The "categs" array stores the categories (BOT, ENT, PAL, ZOO).
In the main command, the first step is to echo a tab-separated header for the table of counts. The command then loops through each of the 2 nested arrays. For each of the categories, the command first echoes the category name. It then greps out the records in "occ2" with that category. In each such record it cuts out the relevant set of fields from the "blanks" array and greps a count of the records with no visible characters in those fields.
The output of the main command looks something like this:
BOT
27736
301987
26371
ENT
28668
etc
A paste command puts the output into tab-separated, 4-field form, in alignment with the already-printed header.
Sod's Law. When I added the table in markdown to a blog post on a public forum, I did it by typing the numbers, and of course made a mistake. The "ENT/where" figure should have been 796119, but I entered "796118". The difference was too small to worry about fixing when I eventually noticed it. Memo to self: copy, do not type.
Next post:
2024-11-01 Timing a CSV to TSV operation
Last update: 2024-10-25
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License