
For a list of BASHing data 2 blog posts see the index page. ![]()
Documenting edits with a before-and-after report
I've tweaked the "reportlist" script in A Data Cleaner's Cookbook to make the results easier to read and more informative.
The new script (I call it "changes") is shown below. For each edit to a data item in a TSV, the script prints to stdout the record ID (from a field with the record's unique ID code), the name of the field containing the data item, and both the original data item and the edited one. Besides displaying the changes in a terminal, the script also sends the report to a text file with a date/time stamp.
To use the script, I first back up the table to be edited by copying it to a table with a different name. For example, an "event.txt" table might be copied to "event-old.txt", or "event-v1.txt" or "event-2024-10-06.txt". I then make any needed edits to data items in the original table, and save the edited table with the original table name. I run the script with the command
changes [backed-up table] [edited table] [number of ID code field]
In the example below, I've made edits in several records in a TSV called "event.txt". I copied the table to "event-old.txt" before editing, and "event.txt" after editing was saved with the original name, "event.txt". The unique ID field eventID was field 1 in this table. Note that the two edits in eventID "TAS-event-3076" are shown separately.
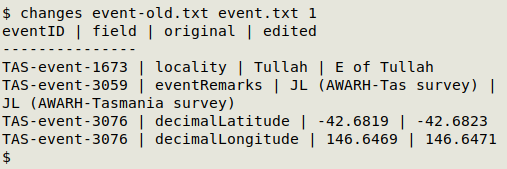
The changes script also built the table "event.txt-edits-2024-08-15T15:43:58.txt" in the same directory as "event.txt". In a text editor, the editing report looks like this:
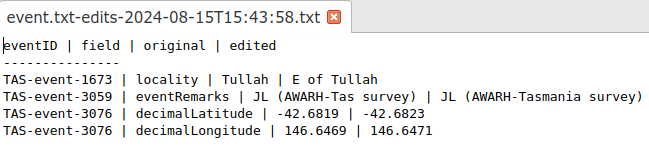
The changes script only shows edits within data items. If I'm editing a table by adding, deleting or moving fields, or by adding, deleting or moving records, I make these changes (and document them) before doing data item edits and reporting them with changes.
#!/bin/bash
paste "$1" "$2" > merged
FN=$(awk -F"\t" 'NR==1 {print NF/2; exit}' merged)
awk -F"\t" -v fn="$FN" -v idfld="$3" \
'NR==1 {for (i=1;i<=fn;i++) a[i]=$i; \
print $idfld FS "field" FS "original" FS "edited\n"} \
NR>1 {for (j=1;j<=fn;j++) if ($j != $(j+fn)) \
print $idfld FS a[j] FS $j FS $(j+fn)}' merged \
| sed 's/^$/---------------/;s/\t/ | /g' \
| tee "$2-edits-$(date +"%Y-%m-%dT%X").txt"
rm merged
exit 0
The "before" and "after" files are merged side-by-side with paste as the temporary file "merged".
The total number of fields is counted with AWK and divided by 2; this result is stored in the variable "FN".
AWK is told that the field separator in "merged" is a tab (-F"\t") and 2 AWK variables are defined. "fn" is the internal AWK variable for the shell variable "FN" (-v fn="$FN") and "idfld" is the internal AWK variable for the shell variable "$3" (-v idfld="$3"), which holds the number of the field containing each record's unique ID code.
AWK looks at the first record, which is the header line in "merged" (NR==1). It loops through the fields in the header up to the last of the original fields (for (i=1;i<=fn;i++)) and builds an array "a" whose index string is the field number and whose value string is the name of the field ( a[i]=$i). AWK then prints the name of the ID field and the strings "field", "original" and "edited", all tab-separated and followed by a newline (print $idfld FS "field" FS "original" FS "edited\n". This creates the header for the before-and-after TSV with a blank line after it.
AWK next moves on to the records after the header (NR>1) and again loops through the fields (for (j=1;j<=fn;j++)). This time it checks to see if each data item in the original (backed-up) table is the same as the corresponding data item in the edited table. If not (if ($j != $(j+fn))), AWK prints the ID code, fieldname, original data item and edited data item (print $idfld FS a[j] FS $j FS $(j+fn)).
The AWK command output is sent to sed, which replaces the blank line under the header with a series of hyphens and replaces all tabs with " | " for clarity (sed 's/^$/---------------/;s/\t/ | /g').
The sed output is sent to tee, which passes that output to stdout but also creates a new text file named with a date/time stamp (tee "$2-edits-$(date +"%Y-%m-%dT%X").txt").
In a final clean-up command, rm deletes the temporary file "merged".
Last update: 2024-09-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License