
For a list of BASHing data 2 blog posts see the index page. ![]()

Mojibake, anyone?
Continuing a series of posts on mojibake, this one looks at some delightful samples in UTF-8 encoding from recent data audits. My reconstructions are only guesswork, but they're plausible.
The first sample started with an iNaturalist observation. The location was "Dagua, Valle del Cauca, Colombia" and the Russian observer transliterated that into:
The Russian word Дагуа in UTF-8 is made up of five 2-byte characters:
d0 94 d0 b0 d0 b3 d1 83 d0 b0 (hexadecimal)
Reading that byte-by-byte in the 1-byte Windows-1252 encoding we get
Read that back into UTF-8 and the 1-byte characters expand to 2-byte and 3-byte ones:
c3 90 e2 80 9d c3 90 c2 b0 c3 90 c2 b3 c3 91 c6 92 c3 90 c2 b0
Read that once again as Windows-1252 1-byte characters to get
where the "?" indicates a byte not assigned to a character in Windows-1252. Now pass the string to a program that ignores the unassigned bytes and translates the others into UTF-8, and for the whole location you get
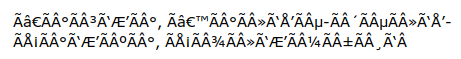
which is the incomprehensible mojibake I found in the audit file. Luckily the file included the URL for that iNaturalist observation. Without that, I can't imagine how I could have reconstructed the original location text.
Etè 1890
This one started as a transcription from a museum specimen label into a database.
I like it because it hints at travel in a time machine, with an ETA (estimated time of arrival) of 1890!
The mojibake string started in UTF-8 with Etè, where è is the 2 bytes c3 a8. Read in Windows-1252 the 2 bytes spell è, and that's how they were read back into UTF-8. But I suspect the original had the French for summer in 1890, Été, and the transcriber (or OCR?) misspelled it.
Forestry Department’s cabin
The original was in Windows-1252 encoding with a right single quote (RSQ) between "t" and "s". In Windows-1252 a RSQ is coded as a single byte, hex value 92. The string then went to a program with UTF-8 encoding, and the RSQ became the three bytes e2 80 99.
The trouble started when the string then went to a Mac. Here the 3 bytes were read as single bytes in the old Mac OS Roman encoding, where e2 is the single low quotation mark ‚, 80 is Ä and 99 is ô. The string went next to a program that converted the three separate characters to UTF-8.
If the three bytes had gone to Windows-1252 again instead of Mac OS Roman, they would have been read as ’.
Capland Süßwassertümpel bei Chapmansbay 8.7.1903
Another museum label transcription. The mojibake started in UTF-8 as Süßwassertümpel, which translates from the German as "freshwater pond", and was represented by the bytes c3 bc for ü and c3 9f for ß. Those bytes were read in Mac OS Roman encoding as the square root sign √ (c3), masculine ordinal indicator º (bc) and ü (9f) before returning to UTF-8.
L. Pe¤a and S‹o Sebasti‹o
These two samples are interesting because all that's changed is a 1-byte character, but they're also puzzling: I haven't yet thought up a possible series of encoding changes that would explain the mojibake. The original of L. Pe¤a was L. Peña and the original of S‹o Sebasti‹o was Sâo Sebastiâo. Suggestions welcome!
Previous posts about mojibake:
- 2018-08-06: Mojibake detective work
- 2019-07-05: Return of the mojibake detective
- 2020-04-01: More mojibake fun
- 2020-12-16: Mojibake bonanza
- 2021-05-19: Mojibake madness
- 2024-02-09: Mojibake with 2 hearts and 52 bytes
Last update: 2024-07-19
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License