
For a full list of BASHing data blog posts see the index page. ![]()
More mojibake fun

For earlier BASHing data detective stories about mojibake, see here and here.
EASY: A disappearing face. From a webpage by Mohamed Aamir Maniar about a new data-transfer format:

This is a reversible replo. The webpage code doesn't specify an encoding, and my Firefox browser guesses the encoding is "Western". If I change the page encoding to "Unicode", a winking-face emoji appears:

The winking face has the codepoint U+1F609 in Unicode, and I suspect the emoji was entered that way in the original webpage text using an emoji-picker. That Unicode codepoint was correctly translated to UTF-8 as a 4-byte character with hex values fo 9f 98 89. If you read that byte-by-byte in Windows-1252 you get 😉.
The safe way to add an emoji to webpage text is to enter it as an HTML code, in this case 😉 (😉). In any case, it's important to specify a webpage's encoding in the "head" section.
The wonderful graphemica.com website has a page with detailed information on the winking-face emoji.
For a complete list of Windows-1252 characters and their encodings, see this fileformat.info page.
MEDIUM: Strange fungus names. I found these 6 garbled names for genera of fungi in a scientific-names look-up table produced by the Atlas of Living Australia (ALA). The strings had been contributed to the table by the Royal Botanic Gardens, Melbourne.
Aseroë
Elsinoë
Helicoön
Naïs
Parepichloë
Zignoëlla
Although the mojibake-d names are also on the ALA website, you get an error if you click on them. For example, here's "Aseroë" on ALA (accessed 2020-03-09):
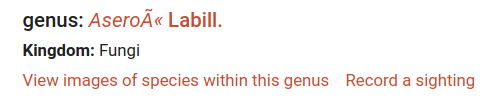
Click on the "Aseroë" link and...
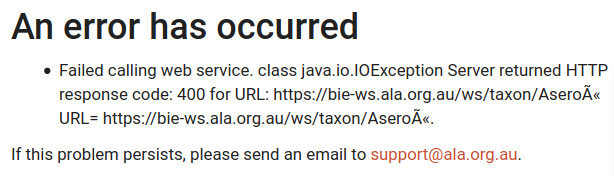
The names contain reconstructable replos. A 2-byte, UTF-8 encoded character was read by a Windows program byte-by-byte to produce 2 new 1-byte characters, and those 2 1-byte characters were converted back to UTF-8 as 2-byte ones.
For example, the 2-byte character ë is encoded as hexadecimal c3 ab in UTF-8. If you read these bytes individually in Windows-1252 encoding, you get à (c3) and « (ab). Converting those 2 characters from Windows-1252 to UTF-8 gives you à (c3 83) and « (c2 ab):
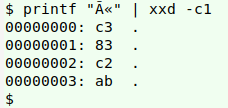
The original genus names are:
Aseroë, Elsinoë, Parepichloë, Zignoëlla
Helicoön
Naïs
A very useful debugging chart for UTF-8 > Windows-1252 > UTF-8 confusion is here.
DIFFICULT: An unsolved mystery. Three names of botanical authors in a UTF-8 file from a herbarium in Brazil have been mojibake-d:
(Čelak.) Y.C.Chu #original, encoding unknown
(-îelak.) Y.C.Chu #UTF-8
(K.Malý) Greuter & Burdet #original, encoding unknown
(K.Mal+¢) Greuter & Burdet #UTF-8
(Üksip) Tzvelev #original, encoding unknown
(+£ksip) Tzvelev #UTF-8
Summary: Č,ý,Ü > -î,+¢,+£
I haven't yet found an encoding conversion that gives this result. If the three characters were originally in UTF-8 and then converted to the ancient CP 850 encoding, you would get ─î,├¢,├£. However, the character before the î is an em dash (hex e2 94), not a hyphen-minus, and the "├" before the cent and pound symbols is a "box drawings light vertical and right" (hex e2 94 9c), not a plus.
Not a character error. In the Reuters online news I occasionally see the odd string <0#FF:>:
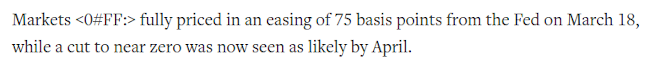
The <0#FF:> string isn't hyperlinked, and I wondered if it was one of those odd angle-bracketed character replacements I'd found before. Maybe "FF" is some sort of code for the form feed character?
No. As a Reuters representative kindly explained in an email:
O#FF is the symbol for the U.S. Fed Fund rate futures on the computer platform used by financial news clients. These symbols sometime migrate into Reuters copy that republishes automatically on Reuters.com.
Puzzle.
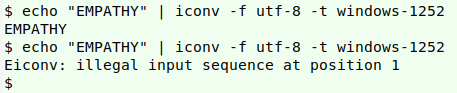
(Explanation in next post.)
Last update: 2020-04-01
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License