
For a list of BASHing data 2 blog posts see the index page. ![]()
CSV to JSON to CSV, awkwardly
In the first BASHing data series I wrote about two developments in the JSON world that allow CLI folk to use everyday tools like GNU "coreutils" and AWK to work with JSON files: JSON Lines and gron the JSON flattener.
What I didn't say is that there's easy JSON and there's difficult JSON, and this post is about the difficult kind.
The dataset in question started out as a simple CSV from the Australian Capital Territory (ACT) government. There's a header and 63 rows with 5 fields each, file size 1.9 kB. The filename is "ACT_estimated_resident_population_2021_by_age_group_and_sex.csv", which I'll shorten here to "original.csv". ("pouplation" in the original CSV's header is an ACT-agency spelling error.)
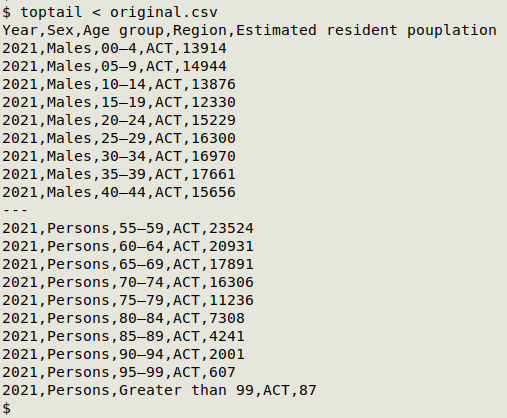
toptail returns the first and last 10 lines. It's the function
toptail() { sed -u '10q'; echo "---"; tail; }
Note that "Year" is "2021" and "Region" is "ACT" for all 63 records. It isn't hard to re-format the raw CSV with GNU datamash as a readable, tab-separated pivot table for the 3 variable fields:
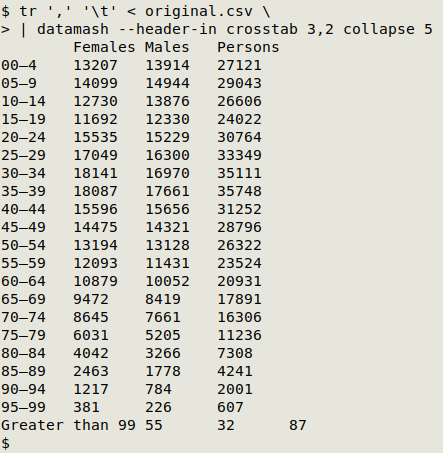
The ACT agency makes the data available in CSV, RDF, RSS, XML, "CSV for Excel", "CSV for Excel (Europe)" and "TSV for Excel" formats. It also offers a JSON file ("8xfv-yddg.json") either as a download or as an API endpoint. The JSON file is very simple: 63 lines, 6.7 kB. It's an array containing various elements, with each element having the 5 fields, and the response header for the API endpoint shows a last-modified date of "Thu, 20 Jan 2022 05:57:37 GMT".

The ACT agency shared a different JSON version with the Australian government's open data portal, namely this one.
The different JSON file (here renamed "act.json") has 474 lines, 22.4 kB. It has a long and elaborate "meta" section and a shorter "data" section. Within the "data" array is a sub-array, and within that sub-array are the records. Each record has 13 fields, and each field is defined and characterised in the "columns" array in the "meta" section. The 13 fields are index-numbered 0-12:
- [0] sid A row ID for the record, e.g. "row-vtbk-k4f6~25y7", as in the ACT agency's RDF, RSS and XML files.
- [1] id A record ID, e.g. "00000000-0000-0000-5CAF-27CEEA8AF929", as in the RSS and XML files.
- [2] position "0" for all records. I'm not sure what this means; it only appears in the XML file as part of the "_rowid" element.
- [3] created_at "1642658257" for all records. This is a UNIX timestamp for 2022-01-20 05:57:37.09, which comes from the RSS file, or possibly a JSON response header.
- [4] created_meta "null" for all records.
- [5] updated_at "1642658257" for all records.
- [6] updated_meta "null" for all records.
- [7] meta "{}" for all records.
- [8] Year As in the CSV.
- [9] Sex As in the CSV.
- [10] Age group As in the CSV.
- [11] Region As in the CSV.
- [12] Estimated resident pouplation [sic!] As in the CSV.
OK, now how to get sex, age group and population out of this more complicated JSON into a usable form, like a CSV?
The best CLI method is to wrangle jq syntax to extract just the array elements you need. I called on paste for the final step, which transforms the stack of jq outputs into a CSV:
jq -r '.data | .[] | .[9,10,12]' act.json | paste -d"," - - -
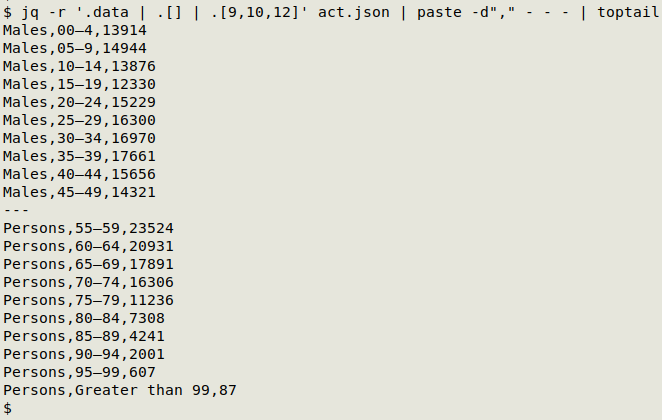
jq reads the "data" array (.data), within which is the unnamed record-holding array (.[]), within which are record elements from which I extract fields 9, 10 and 12. In "act.json" the values are quoted and the -r switch removes the quotes.
gron isn't very helpful in this case. Flattening the JSON gives a pretty but complicated output, shown here for females aged 0-4:

The gron output can be dissected with careful use of AWK to give the same stack of values that you get with jq:
gron act.json | awk -F"[][\"]" '/json.data/ && NF==7 && ($4==9 || $4==10 || $4==12) {print $6}' | paste -d"," - - -
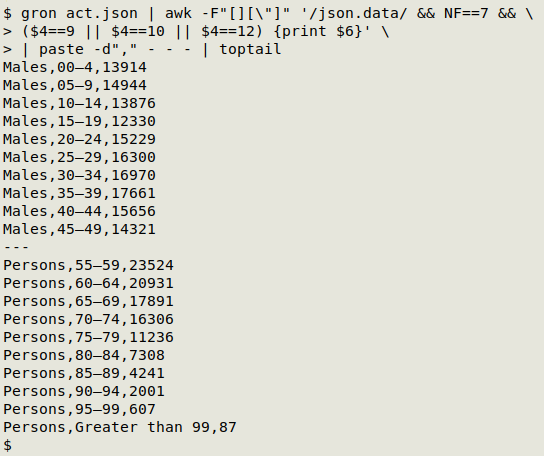
AWK here uses either [ or ] or " as field separator. In a line of interest like json.data[21][9] = "Females";, that makes field 4 the index value 9 and field 6 the entry Females, with 7 the total number of fields. AWK filters standard input to find lines with "json.data" and 7 fields, and prints the field 6 entry if the field 4 index value is 9, 10 or 12.
However, the job can be done just as easily with the unflattened JSON, because "act.json" as a text file has each record on a separate line. The records are on JSON line numbers 412 through 474:
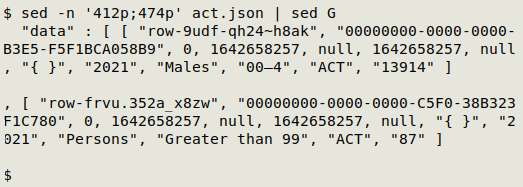
And the CSV can be built from the JSON with a single AWK command:
awk -F"\"" 'NR>411 && NR<475 {print $(NF-7)","$(NF-5)","$(NF-1)}' act.json
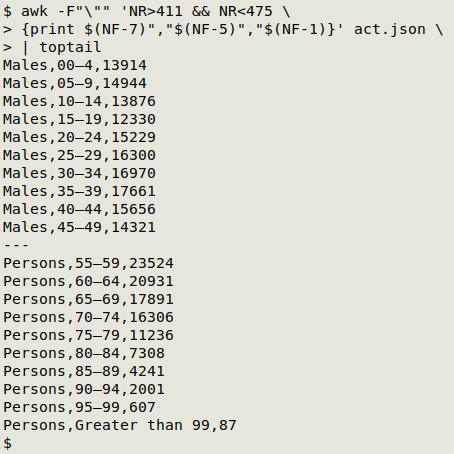
AWK is told to use " as field separator, and to process lines 412 through 474. For each line it prints a comma-separated string of the 3 fields of interest. These are defined by counting back from the last field ($NF), which is " ]" on those lines.
Note that I had to inspect the complicated JSON (the one shared with the Australian government) to get those line numbers, just as I needed to inspect its structure before I could use jq to get the data items I wanted.
Last update: 2024-04-18
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License