
For a full list of BASHing data blog posts see the index page. ![]()
JSON Lines: record-style JSON
There are lots of websites that explain why JSON is so popular. It's based on the familar JavaScript syntax and it has several advantages over CSV, XML and other data transfer formats. To my mind the two key differences between JSON and data tables are:
- In a data table, the position of a data item in a record tells you the field category to which that data item is assigned. In JSON, the position of a data item ("value") doesn't matter, because attached to every data item is the name of its field ("key").
- In a data table it can be hard to retrieve individual data items embedded within another data item. In JSON, "nested" individual data items are easily separated out. They can either be elements of an array, or whole data items (which can themselves contain arrays or data items).
Nevertheless, there are also lots of online services and desktop applications that will convert a big, one-line JSON file into a table-style CSV or TSV for line-by-line processing of records. You might conclude from this that there's no middle ground: you either have your data in JSON or you use a table format.
In fact, there is a middle ground, or rather, several middle grounds. These in-betweens are JSON format variations designed for JSON streaming. The variations allow a JSON-receiving application to know when one JSON object finishes and the next begins. The simplest of these variations (in my view) is JSON Lines. Here's an example — first in JSON format, then in JSON Lines. The example is loosely modelled on the fire ban declarations used in the state of Victoria (Australia):
[{"date":"20/01/2020","bans":0,"byArea":[{"name":"area 1","ban":0},{"name":"area 2","ban":0},{"name":"area 3","ban":0}]},{"date":"21/01/2020","bans":1,"byArea":[{"name":"area 1","ban":1},{"name":"area 2","ban":1},{"name":"area 3","ban":0}]},{"date":"22/01/2020","bans":1,"byArea":[{"name":"area 1","ban":0},{"name":"area 2","ban":1},{"name":"area 3","ban":0}]}]
{"date":"20/01/2020","bans":0,"byArea":[{"name":"area 1","ban":0},{"name":"area 2","ban":0},{"name":"area 3","ban":0}]}
{"date":"21/01/2020","bans":1,"byArea":[{"name":"area 1","ban":1},{"name":"area 2","ban":1},{"name":"area 3","ban":0}]}
{"date":"22/01/2020","bans":1,"byArea":[{"name":"area 1","ban":0},{"name":"area 2","ban":1},{"name":"area 3","ban":0}]}
What's the difference? The JSON is on a single line. The JSON Lines is on three lines, one for each date. Each of those lines is in UTF-8 encoding, ends with a linefeed character and is valid JSON. Those are the only three requirements for the JSON Lines format.
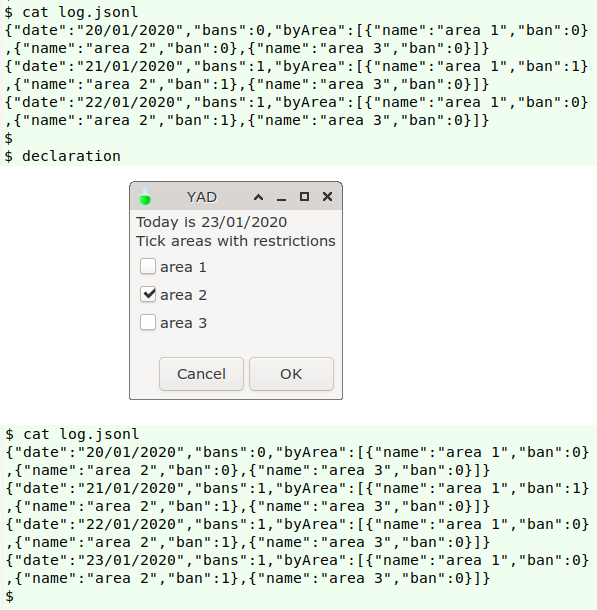
The fire-ban-by-date example shows that JSON Lines is a neat format for data logs. In this case, I could just append a new JSON line to a log file each day with echo and >>. I'd probably use a YAD form, then convert the form output into the full JSON formatting with sed and AWK:
declaration()
{
echo "$(yad --form --separator="\t" \
--text="Today is $(date +"%d/%m/%Y")\nTick areas with restrictions" \
--field="area 1:CHK" \
--field="area 2:CHK" \
--field="area 3:CHK" \
| sed 's/FALSE/0/g;s/TRUE/1/g' \
| awk -F"\t" -v today="$(date +"%d/%m/%Y")" \
'/1/ {x=1} !/1/ {x=0} \
{print "{\"date\":\""today"\",\"bans\":"x",\"byArea\":[{\"name\":\"area 1\",\"ban\":"$1"},{\"name\":\"area 2\",\"ban\":"$2"},{\"name\":\"area 3\",\"ban\":"$3"}]}"; x=""}')" \
>> log.jsonl
}
The commands are shown here as a function for simplicity. In the real world I'd put them in a script with error-proofing!
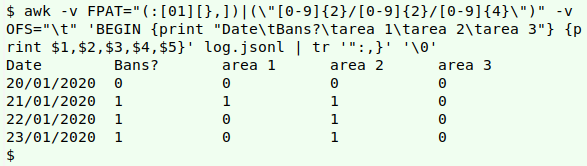
And I can use ordinary line-processing tools, like AWK and tr, to "tabulate" the JSON Lines log:
awk -v FPAT="(:[01][},])|(\"[0-9]{2}/[0-9]{2}/[0-9]{4}\")" -v OFS="\t" 'BEGIN {print "Date\tBans?\tarea 1\tarea 2\tarea 3"} {print $1,$2,$3,$4,$5}' log.jsonl | tr '":,}' '\0'
Not all JSON data is suited to the JSON Lines format, but regularly-structured data will fit in nicely. To convert a JSON Lines file like "log.jsonl" to one-line valid JSON, you only need to add a [ at the beginning and a ] at the end, and replace all but the last newline with a comma. Sounds like a job for AWK:
awk 'BEGIN {printf "["} {printf("%s,",$0)} END {print $0 "]"}' log.jsonl

If you're a Python user, there's a JSON Lines library of tools which can do data validation.
Notes on commands
The YAD form output will be FALSE[tab]TRUE[tab]FALSE for 2020-01-23. sed turns that into 0[tab]1[tab]0. AWK looks for a "1" in this string, and sets the variable "x" to "1" if "1" is found and "0" if it isn't. This "x" value is added to the output as a first tab-separated field ("Bans?"), making 1[tab]0[tab]1[tab]0. AWK then prints a JSON object, inserting these field values and today's date where appropriate.
In the "tabulation" command, AWK looks for fields defined by either of two patterns as regex: (1) a "0" or "1" preceded by a comma and followed by either a closing curly bracket or a comma (:[01][},]), or (2) a date in DD/MM/YYYY format enclosed in double quotes (\"[0-9]{2}/[0-9]{2}/[0-9]{4}\"). It prints the fields in the order it finds them, as (for example) "23/01/2020"[tab]:1,[tab]:0}[tab]:1}[tab]:0}. I would have liked to use tr -d "[[:punct:]]" to clean up this string, but that would also wipe out the / in the date. Instead I used tr '":,}' '\0', which targets the four extraneous characters and replaces them with the null character.
In the AWK command to convert JSON Lines to JSON, note that the action in the END statement applies to the last record in the file. This is the END statement default, and overrides whatever other commands applied to (all) the records.
Last update: 2020-01-29
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License