
For a full list of BASHing data blog posts see the index page. ![]()
A curious pair of data ops
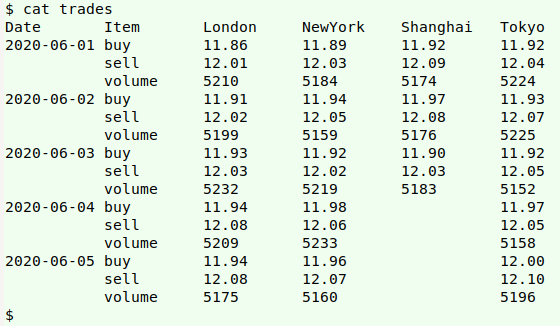
Multiple pivots. The screenshot above shows imaginary daily trades in four different markets. How to extract (from the tab-separated table "trades") the buy/sell/volume figures by day for each of the markets separately? I did it like this:
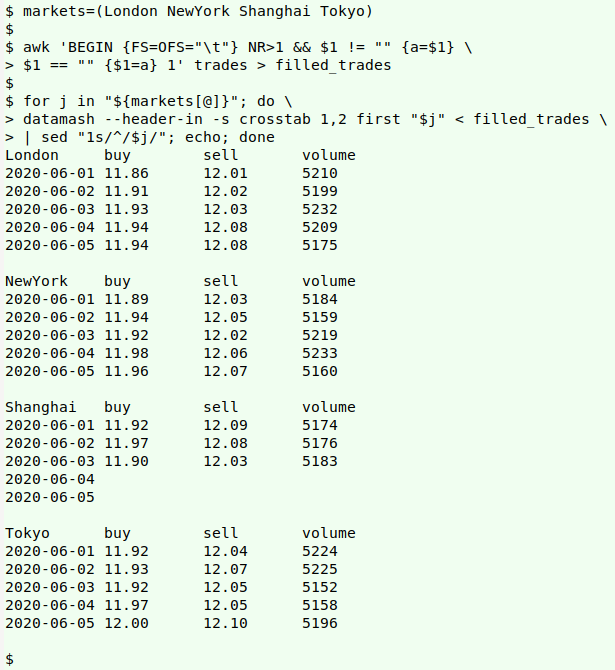
markets=(London NewYork Shanghai Tokyo)
awk 'BEGIN {FS=OFS="\t"} NR>1 && $1 != "" {a=$1} \
$1 == "" {$1=a} 1' trades > filled_trades
for j in "${markets[@]}"; do \
> do datamash --header-in -s crosstab 1,2 first "$j" < filled_trades \
| sed "1s/^/$j/"; echo; done
The key command is the operation with GNU datamash that does a pivot on Date and Item. The tricky part is getting the data ready for the pivoting. For more on datamash pivoting, see this earlier BASHing data post.
The first step is to create a BASH array, "markets", containing the names of the markets. Notice that New York is spelled as one word in "tables" and in the array, for a reason explained below.
Next, AWK fills down the Date column in "trades" with the missing dates. An explanation of this AWK command is in an earlier BASHing data post. Without those dates on each line of the table, datamash can't do the pivoting. The filled-down table is saved as "filled_trades".
The rest of the command is an ordinary BASH for loop, which iterates through the four names in the "markets" array (for j in "${markets[@]}"). At each iteration datamash is given options to let it know there's a header line (--header-in) in "filled_trades" and that I want to pivot on the first 2 fields, Date and Item (crosstab 1,2) with sorting (-s).
I also tell datamash that the field whose values should appear in the output pivot table is the one with a market name. I could have specified this field with a number, such as "3" for "London", but I wanted the market name string for the next step in the loop. Unfortunately, if I use a field name with a space in it, datamash doesn't know what to do and error-messages that field, so "New York" was written "NewYork".
To simply print the values in the market-name fields I used the datamash operation "first", which returns "the first value of the group". Since the group consists of a single value, "first" prints that one value.
The output pivot tables have a blank space over the Date column and I filled that space with the market name string using sed. A final echo spaces the pivot tables before the loop closes.
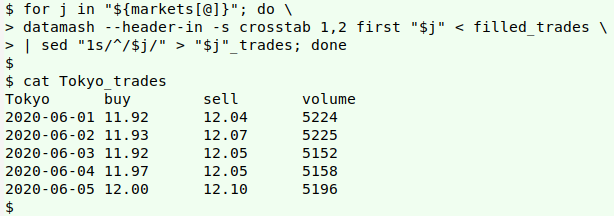
The for loop can be modified to print each market result to a separate file:
markets=(London NewYork Shanghai Tokyo)
for j in "${markets[@]}"; do \
> datamash --header-in -s crosstab 1,2 first "$j" < filled_trades \
| sed "1s/^/$j/" > "$j"_trades; done
I fiddled with a pure AWK approach to this data reformatting, but it was way more complicated than the one shown above.
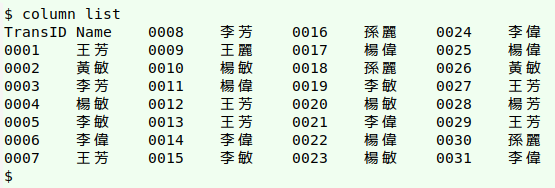
Keying the unreadable. I don't understand Chinese characters. Faced with this tab-separated list of 31 transaction numbers and customer names, how can I assign a unique, 3-digit customer number to each name?
Answer: with AWK. I'll put each of the Chinese-character names as index string into an array "a", and set the value string to an incremented variable "n". I'll then add a field to each record with the "n" value for that customer, formatted as a 3-digit number:
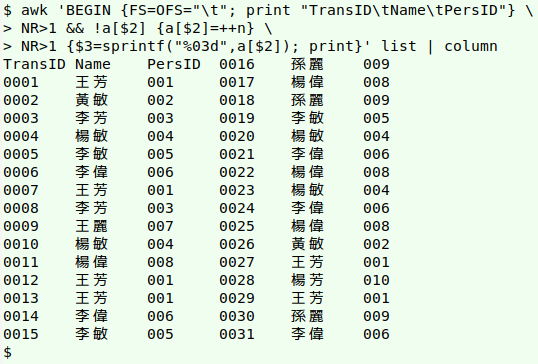
awk 'BEGIN {FS=OFS="\t"; print "TransID\tName\tPersID"} \
> NR>1 && !a[$2] {a[$2]=++n} \
> NR>1 {$3=sprintf("%03d",a[$2]); print}' list
In the BEGIN statement AWK is told to use a tab character as input and output field separator, and to print a new header line. The remaining actions in the command apply only to lines after the original header (NR>1).
The first part of the command checks to see if the contents of the second field are already in an array "a" with field 2 contents as index string (!a[$2]). If not, the field 2 contents are added to the array as an index string. An incremented counter variable "n" (by default, incremented from 1) is assigned to the array as value string.
The second part of the command defines a new, third field as the value string in array "a" for the current line's second field (a[$2]), formatted as a 3-place number with leading zeroes. The formatting is done with sprintf so that the formatted output can be used in another action. That action is print, which by default prints the whole line, including the new field 3.
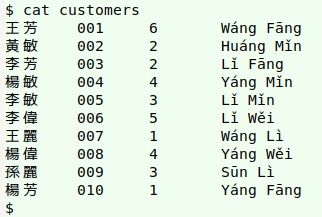
And here's a list of customers by name and customer ID number, together with the number of times each name appears in the list of 31 transactions. I've added here a transliteration of each name into Pinyin (from here).
Last update: 2020-03-18
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License