
For a full list of BASHing data blog posts, see the index page. ![]()
Transpose, pivot and bin with GNU Datamash 1.4
GNU datamash is a command-line data wrangler with a lot of useful capabilities. I downloaded the latest version, 1.4 (December 2018), from the GNU FTP page and built datamash from source.
The online manual is currently for version 1.3, but the only difference between 1.3 and 1.4 seems to be the addition of a "skip comments" option to ignore lines starting with '#' or ';' and optional whitespace.
In this post I test-drive three datamash operations, in two cases comparing them with other command-line tools.
Transposing rows and columns. My test file "occ" has 81909 rows, each of which has 235 tab-separated columns, with an average of 7880 characters per row. The datamash command for transposing a tab-separated table like "occ" couldn't be simpler:
datamash transpose < occ
In the past I used a homemade script based on cut and paste for transposing small data tables, but "occ" would choke it. A faster script for big tables is this AWK one, as improved on Stack Overflow by AWK guru Ed Morton and specified for a tab-separated table in the BEGIN statement:
test.awk:
BEGIN {FS=OFS="\t"} \
{for (rowNr=1;rowNr<=NF;rowNr++) {cell[rowNr,NR]=$rowNr} \
maxRows = (NF > maxRows ? NF : maxRows) \
maxCols = NR} \
END {for (rowNr=1;rowNr<=maxRows;rowNr++) \
{for (colNr=1;colNr<=maxCols;colNr++) \
{printf "%s%s", cell[rowNr,colNr], (colNr < maxCols ? OFS : ORS)}}}
In a test, datamash built the transposed "occ" in less than 1/10 the time that AWK required:
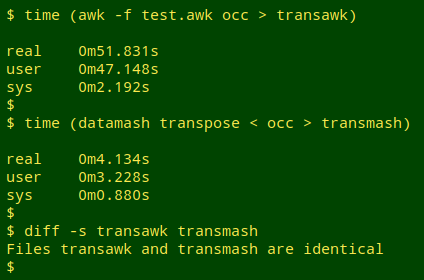
Note that the AWK command puts the entire table into an array in memory.
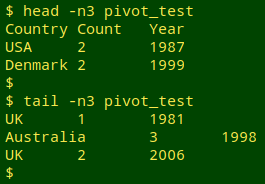
Building a pivot table. The test file this time is "pivot_test", and it's a variant of a file I pivoted in a 2014 Linux Rain post. The tab-separated file contains a header and 3393 lines with 3 fields, Country, Count and Year, where Year runs from 1961 to 2010:
The goal is to generate a pivot table with a sum of the counts by country and year. The basic datamash command would be:
datamash --header-in --filler="0" -s crosstab 1,3 sum 2 < pivot_test
where --header-in tells datamash to ignore the header line, crosstab 1,3 tells it to pivot using fields 1 and 3 (tab-separated fields are the default for datamash), -s tells it to sort the pivoting fields and sum 2 sums the counts in field 2. If there are no counts to be summed, datamash would insert "N/A", but --filler="0" replaces that "N/A" with "0". I'll put "Year/Country" in the gap at the top left of the pivot table with a follow-up sed command:
datamash --header-in --filler="0" -s crosstab 1,3 sum 2 < pivot_test \
| sed '1s/^/Year\/Country/' > pivot_mash
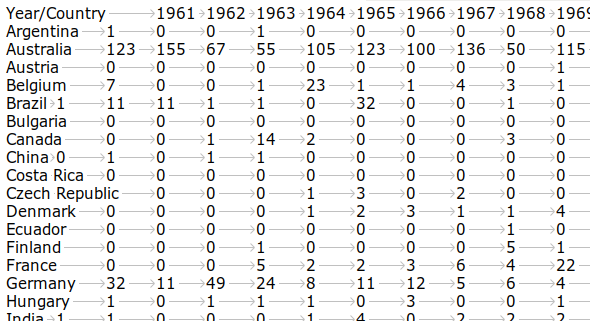
The screenshot below shows the top left of the output file "pivot_mash" in Geany text editor, with tabs represented by faint gray arrows:
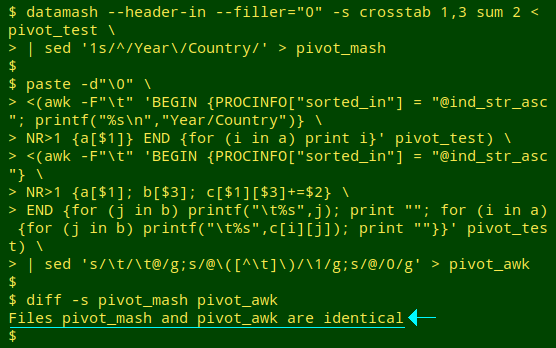
Taking a deep breath, I'll do the same pivoting with AWK, with a couple of improvements over the command I used in 2014:
paste -d"\0" \
<(awk -F"\t" 'BEGIN {PROCINFO["sorted_in"] = "@ind_str_asc"; printf("%s\n","Year/Country")} \
NR>1 {a[$1]} END {for (i in a) print i}' pivot_test) \
<(awk -F"\t" 'BEGIN {PROCINFO["sorted_in"] = "@ind_str_asc"} \
NR>1 {a[$1]; b[$3]; c[$1][$3]+=$2} \
END {for (j in b) printf("\t%s",j); print ""; for (i in a) {for (j in b) printf("\t%s",c[i][j]); print ""}}' pivot_test) \
| sed 's/\t/\t@/g;s/@\([^\t]\)/\1/g;s/@/0/g' > pivot_awk
This gives the same result as datamash, but I never want to write that code again.
Binning numerical data. A particularly useful datamash operation is binning. The following example uses "latlons", which is an unsorted, tab-separated table of 6333 latitude/longitude locations in decimal degrees from my home state of Tasmania.
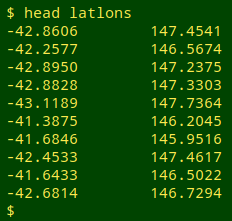
The binning command I'll use is:
datamash --full bin:0.5 1,2
--full means that the output lines will include the original data, bin:0.5 bins the lat/lons in 0.5 degree lots and 1,2 names the fields to be binned:
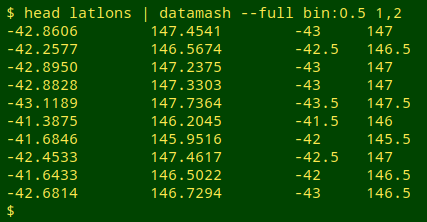
Notice that each binning category is named as the lower end of the binned range.
Now I'll combine binning with pivoting to count the number of lat/lons in each 0.5-degree latitude and longitude bin:
datamash --full bin:0.5 1,2 < latlons | datamash --filler="0" -s crosstab 3,4
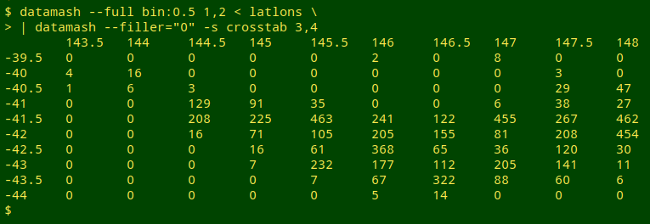
Conclusion? I'm convinced — datamash is an excellent program that can save me a lot of time and effort on the command line.
Last update: 2021-12-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License