
For a full list of BASHing data blog posts see the index page. ![]()
Topping and tailing, and the slowness of GNU sort — updated
The most-used function in my data auditing work is tally. tally takes all the data items from a single field in a tab-separated table except the one in the header line, then sorts the items, uniquifies them and reports their frequencies. The function takes filename and field number as its two arguments. Here, for example, is a tally of the "State" field (field 3) in the table "events":
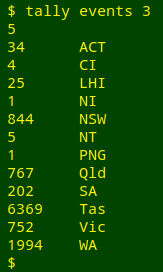
tally() { tail -n +2 "$1" | cut -f"$2" | sort | uniq -c | sed 's/^[ ]*//;s/ /\t/'; }
The sed part tweaks the output from uniq -c, left-justifying the number and separating it from the data item with a tab.
I run tally sequentially on a series of fields. To move from one field to another, I just up-arrow to repeat the command, backspace the old field number and replace it with the new field number. If I expect the field to have many different data items, I pipe the output of tally to less for paging, or sometimes to column if the data items are all very short strings (like year numbers).
Another way I use tally is for "top and tailing", in other words checking just the first few tallies and the last few. The sort command within tally first lists blanks, then punctuation, then numbers, then letters:
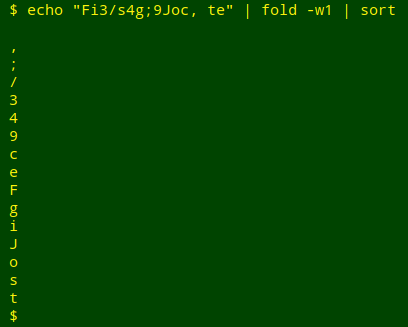
This means that the first few lines from a tally of a supposedly all-alphanumeric field will show if there any blanks in the field, or strings beginning with punctuation. The last few lines from a tally of a supposedly all-numeric field will show if there any alphabetic items. The command I use for "top and tailing" is:
tally [file] [field number] | (head; echo; tail)
which I naturally put into a function, toptail:
toptail() { tally "$1" "$2" | (head; echo; tail); }
Update: The subshell command (head; echo; tail) doesn't always work. I've looked at this issue in another blog post and these two replacements seem to be OK:
toptail() { tally "$1" "$2" | (sed -u 10q; echo; tail); }
toptail() { tally "$1" "$2" | tee >(head >&2) | tail 2>&1; } #No separating space
Here's toptail at work on a real-world dataset:
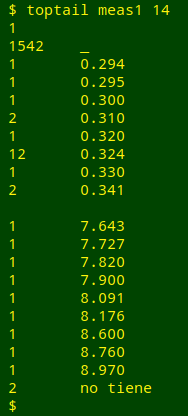
OK, field 14 of "meas1" has a blank where there should probably be an underscore, and the "no tiene" at the end of the tally should probably also be an underscore.
I'd noticed that both tally and toptail ran pretty slowly on big files, and I wondered what the rate-limiting step was. For trial purposes I tallied field 1 of the biggest file I had handy (called "gnames"), a 1.6 GB monster with 23 fields and 5,858,143 lines.
The rate-limiting step turned out to be sorting with GNU sort, as shown here:
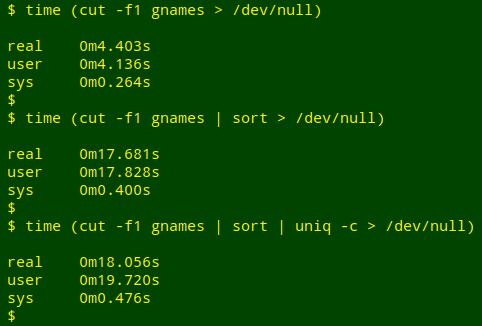
I tried a few different ways to speed up the sorting. Surprisingly (to me, anyway), the best way was to first save the cut-out field to a temporary file, and sort that:
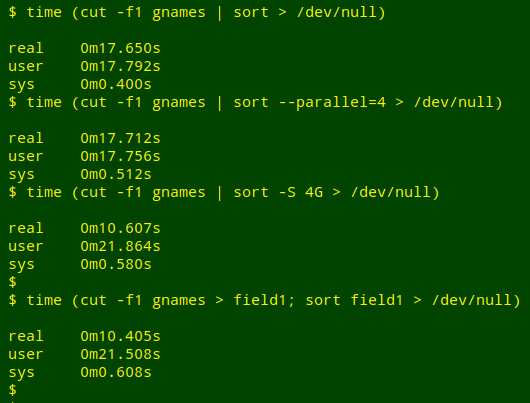
See this Stack Overflow post for reasons why piping to sort is slow.
But that tweak would only be useful for huge files. For my day-to-day work I'm happy with tally and toptail.
Last update: 2020-01-16
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License