
For a full list of BASHing data blog posts, see the index page. ![]()
Horizontal sorting within a field
In the last BASHing data post I wondered whether a certain table might have duplicate but differently sorted lists within a particular field. Here's an example, a tab-separated file called "file":
X01 d,b q,e,a
X02 e,a,b q,c,d
X03 e,d
X04 b q,a,e,c,d
X05 a,c,b q
X06 e,b q,a,d
X07 d,b q,e,a
The second field in the X02 record has the same comma-separated elements as in X04, but in a different order; the same is true for X01 (= X07) and X06. Is there a simple way to detect these duplicates?
I can't think of a simple way, but one approach would be to sort the second field "horizontally" and look for duplicates in that sorted field. The horizontal sorting could be done with either BASH or AWK.
BASH horizontal sorting. Work through the file line-by-line with a while loop. On a cut of the second field, convert the comma-separated list to a newline-separated one with tr, then do a sort, then paste the sorted list back onto a single line with comma as separator. To reconstruct the file with the sorted field last, echo together the original line and the processed second field:
while read line; do echo -e "$line\t$(cut -f2 <<<"$line" | tr ',' '\n' | sort | paste -s -d',')"; done < file
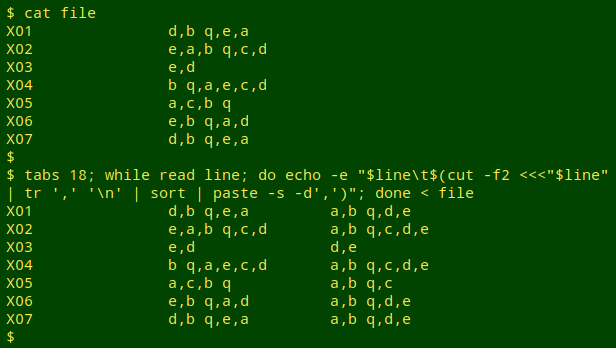
The tabs 18 in the screenshot is just there to space out the fields neatly in my terminal. The next 2 screenshots in this post also have that tabs setting.
AWK horizontal sorting. This requires GNU AWK4. Use the "split" function on field 2, telling AWK that the separator to be used for splitting is a comma; each of the comma-separated elements in field 2 will be put into the array "a" (see command below). Next, walk through the array and print each of the elements, following the element with a comma as in the original file. In the command below, the original line without a trailing newline is "printf-ed" first, then the "split" walk-through is "printf-ed" without newlines, then a newline is printed with print "". The printed-out arrays are magically sorted because the strange-looking instruction PROCINFO["sorted_in"] = "@val_str_asc" is in the BEGIN statement. Note that each horizontally sorted field ends with a comma, which isn't a problem at this stage.
awk -F"\t" 'BEGIN {PROCINFO["sorted_in"] = "@val_str_asc"} {printf("%s\t",$0)} {split($2,a,","); for (i in a) printf("%s,",a[i])} {print ""}' file
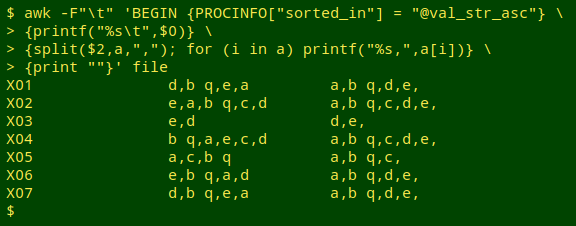
For more on @val_str_asc and array sorting, see this page in the GNU AWK 4 manual.
Extracting duplicates. A quick way to pull out the duplicates in field 3 is to use the one-pass partial duplicate finder explained in this BASHing data post, followed by a sorting and uniquifying. I'll do this on the AWK version of the horizontal sort, and throw in a sed tweak at the end to remove the final commas:
awk -F"\t" 'BEGIN {PROCINFO["sorted_in"] = "@val_str_asc"} {printf("%s\t",$0)} {split($2,a,","); for (i in a) printf("%s,",a[i])} {print ""}' file | awk -F"\t" 'c=b[$3] {print c"\n"$0} {b[$3]=$0}' | sort -t $'\t' -k3 -k1 | uniq | sed 's/,$//'
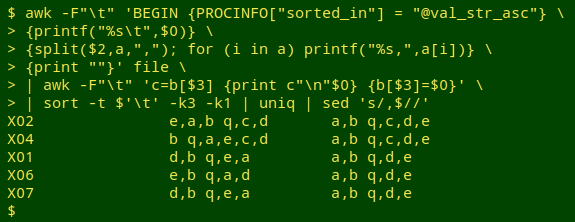
My original question had to do with finding differently sorted, duplicate lists in a big file. The answers above will generate big output files if there are lots of exact duplicate entries in field 2, e.g. hundreds of records with "d,b q,e,a". To simplify those lists, I would cut out the original and horizontally sorted fields (fields 2 and 3 in the demonstrations) from the final output, pass them to sort -t $'\t' -k2 and uniq -c, and check to see how many records had each of the different sortings of the same elements.
Last update: 2019-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License