
For a list of BASHing data 2 blog posts see the index page. ![]()
The ìèñëèâñüêå mystery
I audited a Ukrainian dataset that had both Latin-character data items and Cyrillic-character ones. An example of the Cyrillic items is
Голованівське мисливське господарство
The dataset was revised, and when I saw it again all the Cyrillic data items had turned into gibberish. The example above was now
Ãîëîâàí³âñüêå ìèñëèâñüêå ãîñïîäàðñòâî
This was very strange mojibake. It was a one-for-one character replacement, and both the original Cyrillic and the derived gibberish were in UTF-8, with no obvious connection between the multibyte UTF-8 values.
Even stranger, it wasn't hard to find the same gibberish online:

A probable solution to the mystery is that the original characters were encoded in 1-byte Windows-1251:
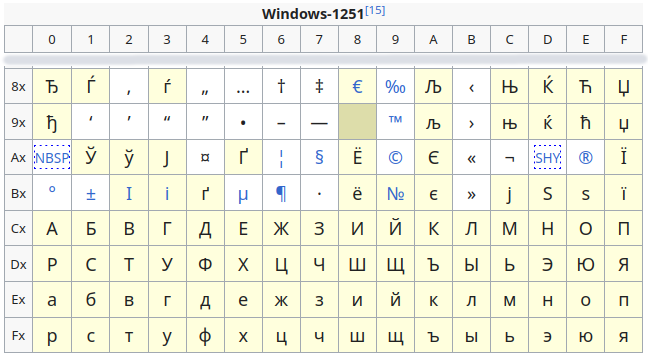
These were then converted to UTF-8 in the first version of the dataset I audited. During the revision of the original data, the 1-byte characters were mistakenly read as Windows-1252:
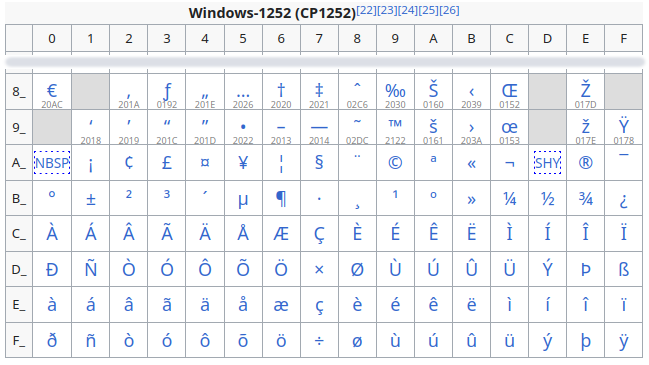
and then converted to UTF-8. iconv supports this idea:
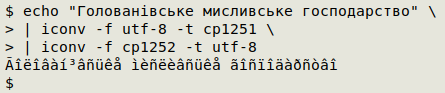
One fine, glorious day in the future, Microsoft will move its applications to Unicode and join the rest of us. Until then, we'll just have to put up with ìèñëèâñüêå.
Next post:
2025-02-07 AWK's view of existence
Last update: 2025-01-31
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License