
For a list of BASHing data 2 blog posts see the index page. ![]()
A Unicode normalisation problem
The following text was posted on a Stack Exchange forum in 2012:
supposed to undergo yearly cardiac exam in order to stay on transplant list. But, there are > patients who are missing important cardiac information. It is yo ur job as an intern on call to make sure that you fin
The SE user asked "Is there a way to fix this?" and the answer is "Yes", but "this" needs explaining. The funny-looking characters aren't in a different font. They're perfectly good UTF-8 characters from the "full-width" portion of the Unicode block Halfwidth and Fullwidth Forms.
The easy fix. The process of replacing complicated Unicode characters with their simplest equivalents is called "Unicode normalisation". For example, the simplest equivalent of the full-width character "j" is the ASCII "j". To normalise on the command line you can use the uconv command from the libicu-dev package. Here I've saved the puzzling text above as the text file "puzzling":

uconv -f utf-8 -t utf-8 -x '::nfkc;' puzzling
uconv is an encoding converter, like iconv, but it can also do transliteration with its -x option. In this case I've used the ::nfkc; method of transliteration, which tells uconv to "decompose complicated characters and reconstitute them in their simplest compatible form, leaving simple characters untouched".
The fix isn't perfect because there's an unwanted space between "yo" and "ur" and between "to" and "make", and I doubt that the ">" should be there, but those can be hand-edited.
A more interesting fix. Another approach to repair would be to make up a table with the full-width characters and their desired replacements, then use the table for substitutions. This is easier to do than it sounds and it only requires standard shell tools, not the ca 50 MB libicu-dev package!
The 96 full-width characters run from U+FF01 to U+FF60. I can display them like this:
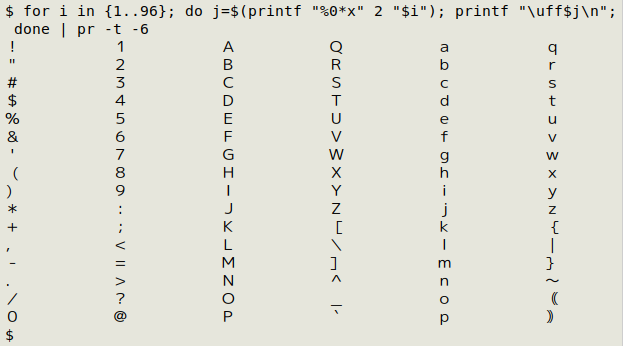
for i in {1..96}; do j=$(printf "%0*x" 2 "$i"); printf "\uff$j\n"; done | pr -t -6
The command builds "\uffNN" strings and lets printf print them as a list in the terminal, with piping to pr -t -6 to display the list as 6 columns. The string building is done with a for loop that runs through the decimal numbers 1 to 96. printf prints each number as a hexadecimal with maximum width 2, so that "1" is printed "01" (printf "%0*x" 2 "$i"). Each hexadecimal is temporarily stored in the variable "j", and each "j" is patched into the string "\uff.." and followed by a newline (printf "\uff$j\n").
If that order of listing looks familiar, it's because it's exactly the same order as the ASCII characters with decimal values 33-127, although the last 2 double parentheses aren't there in ASCII:
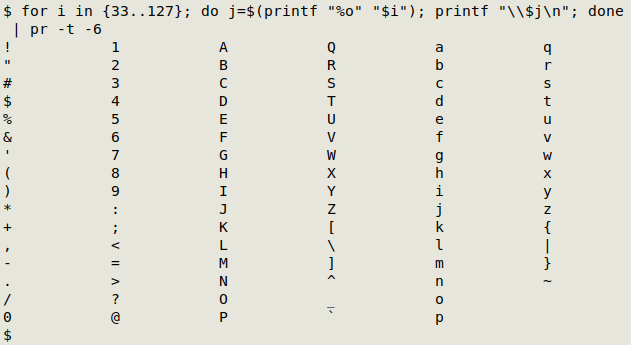
for i in {33..127}; do j=$(printf "%o" "$i"); printf "\\$j\n"; done | pr -t -6
This time I've converted the decimal numbers 33 to 127 to their octal equivalents (printf "%o") before sending them to printf.
Because the character order is the same, I can build a conversion table ("fwhash") by simply paste-ing together the two character lists with the default tab separator. I'll also remove the full-width double parentheses before pasting ("1..94" instead of "1..96") and delete the last, blank line (sed '$d') created by printing a newline after the last character in each list:
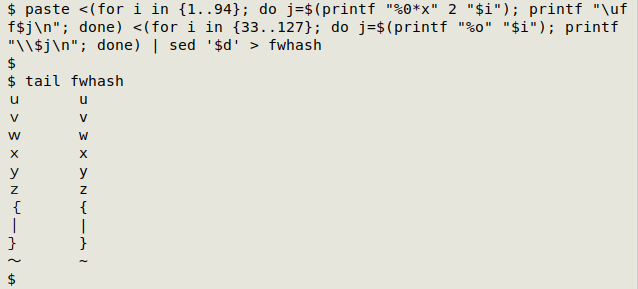
paste <(for i in {1..94}; do j=$(printf "%0*x" 2 "$i"); printf "\uff$j\n"; done) <(for i in {33..127}; do j=$(printf "%o" "$i"); printf "\\$j\n"; done) | sed '$d' > fwhash
Now to apply the table to conversions. I'll use AWK to do that:

The command first builds an array "a" from the "fwhash" table. The full-width character is the array's index string and its ASCII equivalent is the value string. Notice that AWK is told that the field separator in "fwhash" is a tab in a "pseudo-argument" after the command: FNR==NR {a[$1]=$2; next} ... FS="\t" fwhash.
AWK next moves to the text file, and is told its field separator is the empty string: FS="" puzzling. This makes every character in "puzzling" a separate field. AWK loops through "puzzling" character by character (for (i=1;i<=NF;i++)) and checks to see if the character is an index string in the array "a". If it is, AWK prints the replacement from the array. If not, AWK prints the unchanged character (if ($i in a) print a[$i]; else print $i).
AWK prints with a newline, so the output of the command is a long list of characters. To put them all on a single line with no space between them I use paste -s -d"\0".
Well, that almost worked, but there's something strange about the spacing between the formerly full-width characters. Running a sample through xxd reveals that those spaces are not your everyday ones:
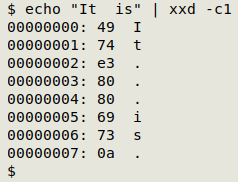
The character with hex value e3 80 80 is something I'd never heard of before, the ideographic space (U+3000) from the Unicode block CJK Symbols and Punctuation. What weird program put those into the original text? In any case, I can replace all ideographic spaces with plain spaces using sed:
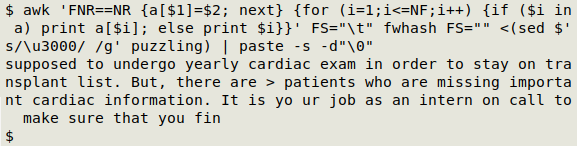
awk 'FNR==NR {a[$1]=$2; next} {for (i=1;i<=NF;i++) {if ($i in a) print a[$i]; else print $i}}' FS="\t" fwhash FS="" <(sed $'s/\u3000/ /g' puzzling) | paste -s -d"\0"
Note the "$" in front of the sed command. This allows BASH to turn "\u3000" into a character for sed to replace.
I now have the same mostly-repaired text that uconv produced, and I had command-line fun building it!
Next post:
2025-01-17 MAD about the median
Last update: 2025-01-10
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License