
For a list of BASHing data 2 blog posts see the index page. ![]()
Numbering duplicates by appearance order and date order
The following table ("birds") has duplicates in the second semicolon-separated field:
id;bird;date
ab1;sparrow;2024-06-11
ab2;blackbird;2024-06-06
ab3;robin;2024-06-01
ab4;finch;2024-06-03
ab5;blackbird;2024-06-15
ab6;finch;2024-06-08
ab7;sparrow;2024-06-07
ab8;finch;2024-06-10
ab9;robin;2024-06-05
ab10;sparrow;2024-06-04
ab11;blackbird;2024-06-13
ab12;dove;2024-06-09
ab13;robin;2024-06-12
ab14;blackbird;2024-06-14
ab15;sparrow;2024-06-02
It's easy enough to add a new field that gives the order in which each bird appears in the table:
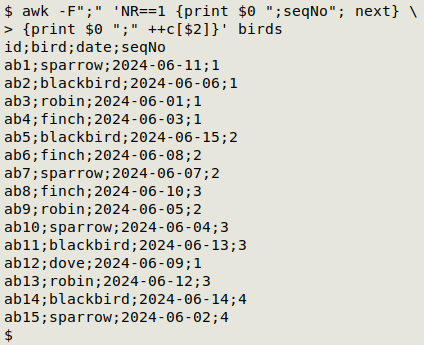
awk -F";" 'NR==1 {print $0 ";seqNo"; next} {print $0 ";" ++c[$2]}' birds
But I could be naughty and put that sequence order right next to the bird name. It's naughty because Databasing 101 teaches that each field should contain one and only one kind of information. However, this result is easier on the eyes and brain:
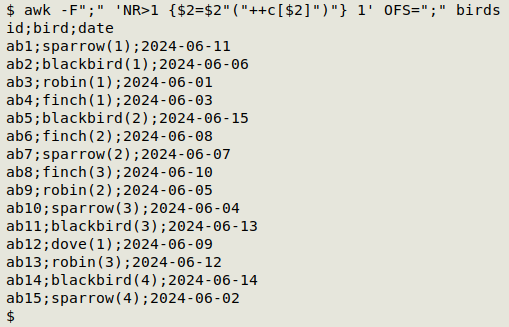
awk -F";" 'NR>1 {$2=$2"("++c[$2]")"} 1' OFS=";" birds
or
awk -F";" 'NR>1 {sub(/$/,"("++c[$2]")",$2)} 1' OFS=";" birds
The "birds" table isn't in chronological order. To order the bird records by date, without altering the id order, I can call in some other shell tools:
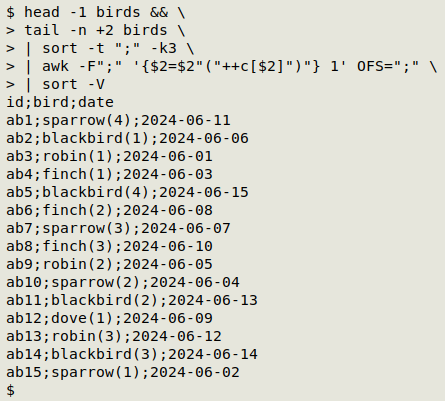
head -1 birds && tail -n +2 birds | sort -t ";" -k3 | awk -F";" '{$2=$2"("++c[$2]")"} 1' OFS=";" | sort -V
And I can check that operation by re-sorting chronologically, rather than by id:
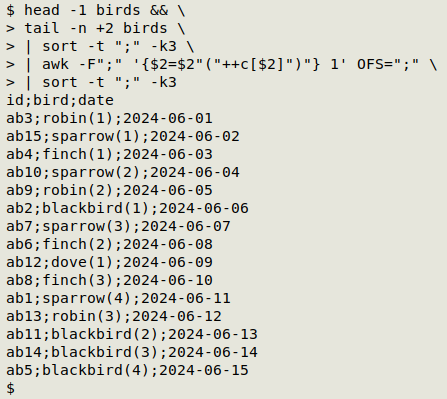
Notes on commands:
"++c[$2]" is the value string in an array "c" that keeps a count of each unique item in field 2; the unique items are the index strings in the array. The counts are pre-incremented, meaning they start with 1 (see this BASHing data 2 post).
sort -V in the chronological command gives "ab1 ab2 ab3 ... ab10 ab11...". Ordinary sort would give "ab1 ab10 ab11 ... ab2 ab3...".
Next post:
2024-12-27 The browser-as-text-editor trick
Last update: 2024-12-20
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License