
For a list of BASHing data 2 blog posts see the index page. ![]()
Sorting camels, kebabs, pascals and snakes
I use GNU sort a lot but I sometimes get unexpected sortings, especially with camel case words. Sorting order depends on locale, so I decided to try a couple of locale experiments using variations on camel case (helloWorld), kebab case (hello-world), pascal case (HelloWorld) and snake case (hello_world). The trial list (filename "case") was:
hello world
Hello world
hello World
Hello World
hello_world
Hello_world
hello_World
Hello_World
hello-world
Hello-world
hello-World
Hello-World
helloworld
Helloworld
helloWorld
HelloWorld
My locale here at home is "en_AU.UTF-8". I compared that with the standard C locale:
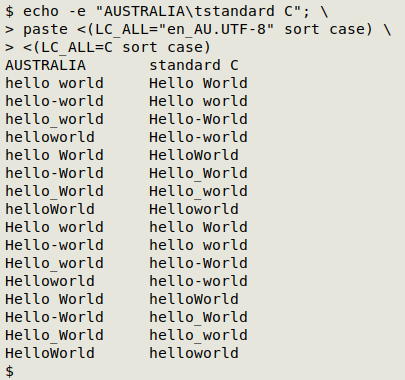
echo -e "AUSTRALIA\tstandard C"; paste <(LC_ALL="en_AU.UTF-8" sort case) <(LC_ALL=C sort case)
So with the "en_AU.UTF-8" sorting rules, lowercase sorts before uppercase, while C sorts uppercase before lowercase. There's another difference, too. GNU sort in the Australian English locale seems to completely ignore what's between the two words and puts "hello[whatever]world" before "hello[whatever]World", and "Hello[whatever]world" before "Hello[whatever]World". The C locale sorting is apparently more complicated. For space-, kebab- and snake-separated words, uppercase "W" comes first in a pair, but not for joined words. For example, camel case "helloWorld" sorts immediately before snake case "hello_World" and "hello_world", leaving the joined "helloworld" for last.
What's happening is that the C sort order follows the ASCII byte values for the characters after the "o" in "hello": space = 32 (decimal), hyphen minus = 45, uppercase W = 87, underscore = 95, lowercase w = 119. The same numbers apply in UTF-8, but have been over-ridden with the lowercase/uppercase rule in my locale.
Non-shell programs might do their default sorting differently, too. The screenshot below shows sorts of "case" in Gnumeric spreadsheet (left) and ModernCSV table editor (right). Gnumeric neatly interleaves lowercase and uppercase, while ModernCSV does a simple C-style sort.
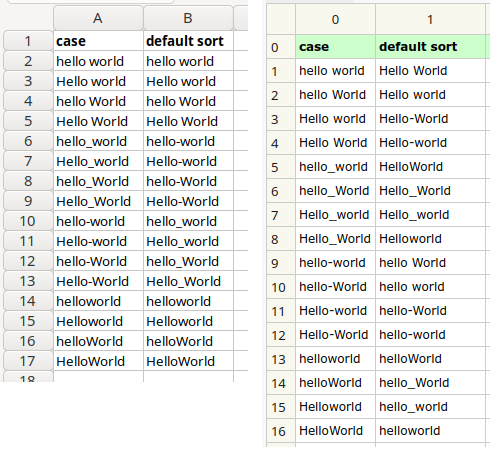
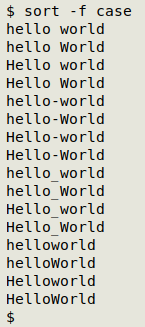
The Gnumeric result resembles the kind of ordering you might find in a dictionary, where case is ignored in the ordering. GNU sort has a case-ignoring option, -f, but the sort isn't neatly interleaved:
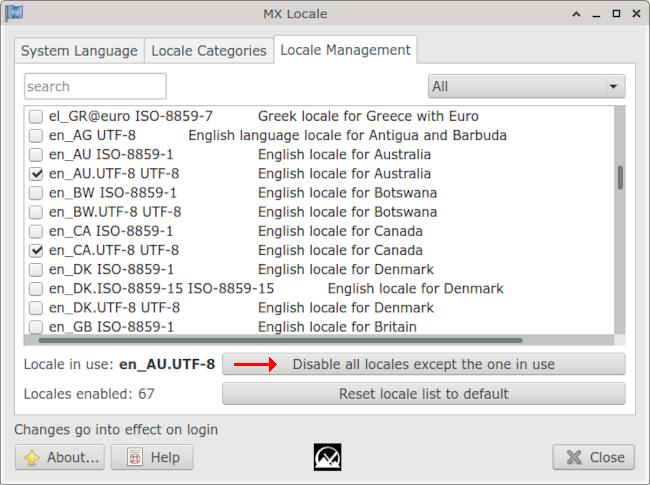
I'll keep using the Australian English UTF-8 locale on the CLI unless there's a camel case issue for which the C locale would be a better choice. By default, my MX Linux 23 OS enables 67 different locales with the system locale set to "en_AU.UTF-8". MX has a nice GUI tool, however, that's invoked with mx-locale on the command line or in the menus with MX Tools/MX Locale. It allows the user to disable all locales except the one in use:
Next post:
2024-12-20 Numbering duplicates by appearance order and date order
Last update: 2024-12-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License