
For a list of BASHing data 2 blog posts see the index page. ![]()
Merging tables with (some) shared fields
This post is based on a data processing job I did last month that involved 11 tables, 74 fields and thousands of records. To simplify the story a lot, here are 3 small tab-separated tables with some shared fields:
Copy and paste the tables from this webpage and they should be tab-separated in your text editor.
table1:
| fld1 | fld2 | fld4 |
| aaa | bbb | ccc |
| ddd | eee | fff |
| ggg | hhh | iii |
table2:
| fld2 | fld3 | fld4 | fld6 |
| jjj | kkk | lll | mmm |
| nnn | ooo | ppp | qqq |
table3:
| fld1 | fld3 | fld5 |
| rrr | sss | ttt |
| uuu | vvv | www |
| xxx | yyy | zzz |
| 111 | 222 | 333 |
The aim is to merge the tables on the command line into one table with fields 1 to 6 (fld1-fld6).
Building a "who has what?" table. This step isn't necessary for the merge, but an overview of which fields are in which table can be useful.
The first stage is a BASH for loop that works through the 3 tables. With each table, the header line with field names is converted to a list and sorted, and the list is fed to AWK. For each listed field, AWK prints the table name, the field name and a "1":
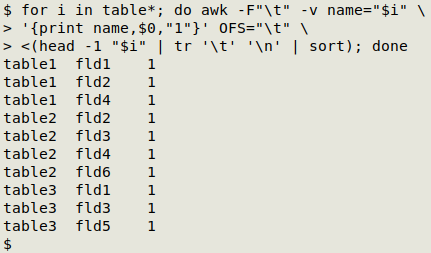
This output is then passed to GNU datamash to build a pivot table. In the pivot table, I've specified "0" as filler for missing items:
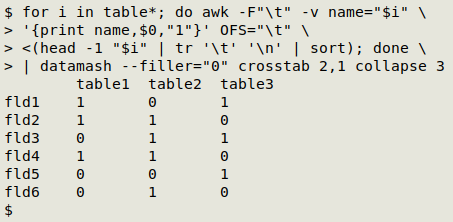
for i in table*; do awk -F"\t" -v name="$i" '{print name,$0,"1"}' OFS="\t" <(head -1 "$i" | tr '\t' '\n' | sort); done | datamash --filler="0" crosstab 2,1 collapse 3
Building the merged table. This method is based on the datamash "transpose" command and the GNU join command. There are other ways I might have done the merge, but this one suited the datasets at hand.
The first step is to create a sorted list (named "fields") of all fields in the 3 tables. To do this I can gather up the field names from the header lines of the 3 tables, then sort the resulting list and uniquify it:
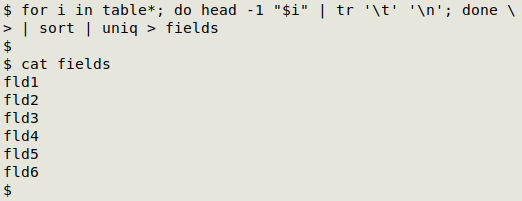
for i in table*; do head -1 "$i" | tr '\t' '\n'; done | sort | uniq > fields
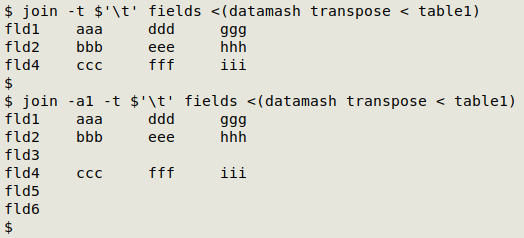
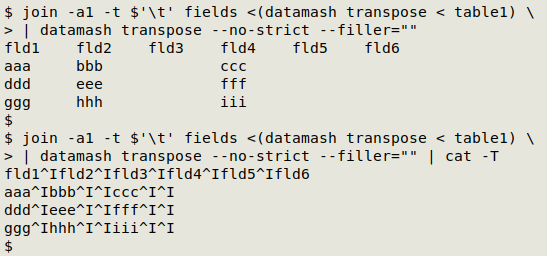
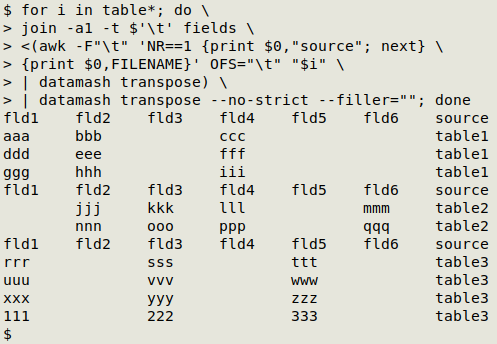
The join command works line by line, looking for lines in the files to be joined that have the same item in the first field. If I transpose "table1" with datamash and do a join with "fields", join returns the lines with the field names common to the two files. (Note in the screenshot that I've specified the tab character as field separator with -t $'\t'). If I add the -a1 option to the command, join also prints the field names from "fields" that it did not find in "table1":
I can get that result back in the original table form with another "transpose" command, this time specifying that the filler for missing values is the empty string (--filler="") and allowing datamash to ignore the fact that there are missing items (--no-strict). The result is a fully tab-separated table with all 6 fields:
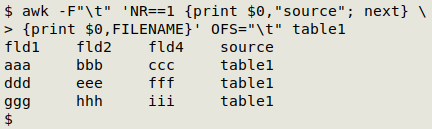
What I haven't done, though, is include the table name in these results. I needed that in my data processing job, so here I'll use an AWK command to add a new field, "source", to the end of the table, and add the table name to every record:
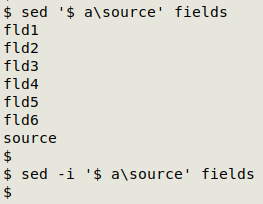
With a new field to be handled by join, I need to edit "fields" to include "source" in its correctly sorted position (in this case at the bottom of the list):
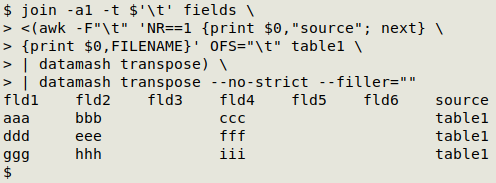
All good, "table 1" can now be fitted into the 7-field structure:
The last-step-but-one is to wrap the command chain in a for loop to process the 3 tables separately:
And the last step is to tidy out those superfluous header lines with awk '!arr[$0]++', a handy command that removes duplicate lines without changing the line order:
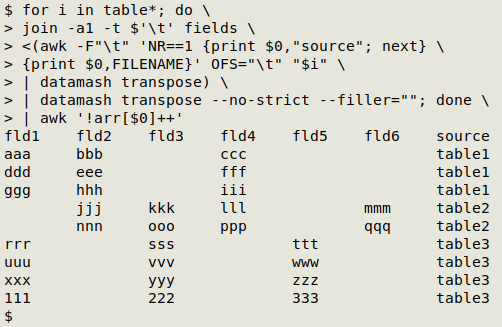
for i in table*; do join -a1 -t $'\t' fields <(awk -F"\t" 'NR==1 {print $0,"source"; next} {print $0,FILENAME}' OFS="\t" "$i" | datamash transpose) | datamash transpose --no-strict --filler=""; done | awk '!arr[$0]++'
In doing the real-world job I had some trouble getting the sort order of the fields in "fields" to agree with the various sort orders of field names in the 11 tables. Without that agreement, join complains. The complaints stopped when I added "| sort -t $'\t' -k1,1" after the first transpose.
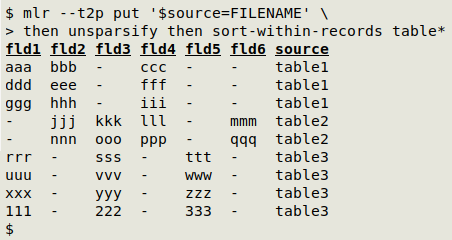
UPDATE 2024-11-20. Reader Andrea Borruso offers a more direct way to do this job, for users of the miller program:
mlr --t2p put '$source=FILENAME' then unsparsify then sort-within-records table*
Next post:
2024-11-22 The Web's most familiar gibberish: ’
Last update: 2024-11-15
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License