
For a list of BASHing data 2 blog posts see the index page. ![]()
USV: The Unicode Separated Values format
Tables are the most familiar form of structured data. They contain text in records (rows) divided neatly into fields (columns), and all sorts of text-using programs understand how to display that structure. Look, for example, at the tab-separated table "demo":

In each case all I did was enter [program] demo on the command line (or cat demo in the terminal). The program then opened with the table displayed correctly as 2 records divided into 3 fields. But the text file "demo" doesn't look like a table. It's just the string
aa\tbb\tcc\ndd\tee\tff\n
where the data content of the TSV is "aa","bb","cc","dd","ee" and "ff". The invisible characters "\t" (tab) and "\n" (linefeed) are structural control elements that tell the table-displaying program how to lay out the data content.
These control elements could be varied without affecting the table's data content. I could have separated the fields with commas (CSV), semicolons (CSV) or pipes (PSV), and if I was running Windows (Heaven help me...) I could have separated records with the 2 characters "\r\n" (carriage return + linefeed).
All of this will be pretty obvious and familiar to most readers of this blog. Not so well-known is the fact that the ASCII character set already contains an invisible character whose purpose is exactly the one for which the linefeed is commonly used, namely separating records. It's called "record separator": RS, hexadecimal 1e, octal 036. In Unicode there's a visible version, U+241E. Here's what "demoRS" looks like in the mousepad text editor with field-separating commas and a visible record separator:
printf "aa,bb,cc\u241edd,ee,ff\u241e" > demoRS
ASCII also contains invisible "structure control" characters which can be used to separate fields or text elements within fields, namely "unit separator" (US, 1F, 037; visibly U+241F) and "group separator" (GS, 1D, 035; visibly U+241D). Here I'm visibly separating the fields in "demo" with US instead of tabs to build "demoUS", shown below as it looks in mousepad:
printf "aa\u241fbb\u241fcc\u241edd\u241fee\u241fff\u241e" > demoUS
This way of structuring table data has been proposed as a new standard in 2024, Unicode Separated Values (USV). It uses existing but neglected ASCII characters and avoids the horrors of CSV and the ambiguities of TSV and PSV. Other advantages and disadvantages are clearly set out in the principal proponent's GitHub documentation.
The proposed standard also includes the invisible file separator character (FS, 1c, 034; visibly U+241c) and it suggests using the invisible "end of transmission" character (EOT, 04, 004; visibly U+2404) to mark the end of a table or data stream. Ordinary linefeeds and carriage returns are also allowed.
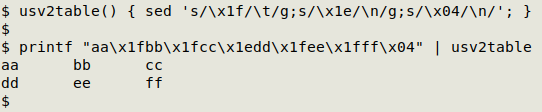
If USV is accepted, table-displaying programs will need to understand what a .usv file is and what those invisible ASCII characters mean for structuring the display. In the meantime, it's easy enough to translate USV with a shell function. To build the "demo" TSV from a USV string with US, RS and EOT in hexadecimal, here's a sed command that converts US to tab and both RS and EOT to linefeed:
usv2table() { sed 's/\x1f/\t/g;s/\x1e/\n/;s/\x04/\n/'; }
printf "aa\x1fbb\x1fcc\x1edd\x1fee\x1fff\x04"
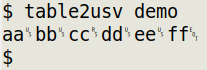
And I can use sed and paste to generate a "visible" USV string from a TSV table:
table2usv() { sed $'s/\t/\u241f/g;s/$/\u241e/g;$s/\u241e$/\u2404/' "$1" \
| paste -sd"\0"; }
Coming up:
2024-10-18 How to force a preferred array sort in AWK
2024-10-25 Anatomy of a data analysis
2024-11-01 Easy and not-so-easy ways to time a process
2024-11-08 Pretty-printing a table in the terminal
Last update: 2024-10-11
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License