
For a list of BASHing data 2 blog posts see the index page. ![]()
Summing by type in a table
Here's a tally of fruits purchased by date (the file "fruits"):
Date;tally
2024-09-01;2 apples, 6 bananas
2024-09-02;4 bananas, 2 melons, 3 pears
2024-09-03;3 apples, 2 melons, 2 pears
2024-09-04;3 apples, 2 bananas
2024-09-05;6 bananas
2024-09-06;2 melons, 5 pears
2024-09-07;1 apples, 2 pears
How to get the total tally for the week, namely "9 apples, 18 bananas, 6 melons, 12 pears"?
I know, I know. This is an awkward way to keep a tally. It would be better to have separate CSV fields for each fruit, like this (the file "fruitflds"):
Date;apples;bananas;melons;pears
2024-09-01;2;6;;
2024-09-02;;4;2;3
2024-09-03;3;;2;2
2024-09-04;3;2;;
2024-09-05;;6;;
2024-09-06;;;2;5
2024-09-07;1;;;2
Given that "fruitflds" table, I could write a command that gives me just the required output:
awk -F";" 'NR==1 {for (i=2;i<=NF;i++) fruit[i]=$i; next} \
{for (i=2;i<=NF;i++) total[i]+=$i} \
END {for (i=2;i<=NF;i++) printf("%s %s, ",total[i],fruit[i]); print ""}' fruitflds \
| sed 's/, $//'
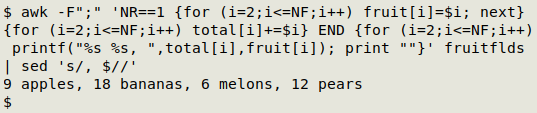
AWK is first told that the field separator in "fruitflds" is a semicolon (-F";"). In the first line (NR==1), AWK loops through all the fields from the 2nd one forward (for (i=2;i<=NF;i++)) and stores the fruit names as value strings in an array "fruit" whose index string is the field number (fruit[i]=$i).
Moving to the second line and subsequent lines (next), AWK again loops through all the fields from the 2nd one forward (for (i=2;i<=NF;i++)), but this time builds an array "total" which contains a growing sum of the numbers in that field (total[i]+=$i).
In an END statement, AWK once again loops through all the fields from the 2nd one forward (for (i=2;i<=NF;i++)), and for each field prints the total number for the field, a space, the fruit name, a comma and a space, but without a newline after each (printf("%s %s, ",total[i],fruit[i]). AWK then prints a newline (print "") and exits.
A final sed command tidies the result by deleting the final comma and space (sed 's/, $//').
Unfortunately, some of the data tables I audit are "fruits" style, not "fruitflds" style, and I need to do operations on numbers by their types (apples, bananas etc). Two strategies are:
- Convert the table from "fruits" to "fruitflds" style
- Work with the "fruits" style, as-is
Below I tinker with both strategies.
Convert "fruits" to "fruitflds". This is a useful strategy because I might want to do something with the converted table besides summing up the different types.
awk -F"[;,]" 'BEGIN {frts="apples;bananas;melons;pears"; \
print "Date;"frts; split(frts,a,";")} \
NR>1 {x=frts; for (i in a) \
{for (j=2;j<=NF;j++) \
{if ($j ~ a[i]) {split($j,b," "); sub(a[i],b[1],x)}}} \
gsub(/[[:alpha:]]/,"",x); print $1";"x}' fruits
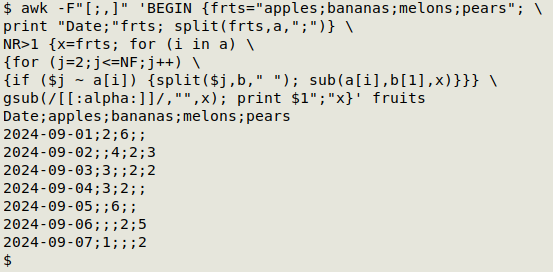
AWK is first told that the field separator in "fruits" is either a semicolon or a comma (-F"[;,]"). In a BEGIN statement I save a semicolon-separated list of fruit names in the table in the AWK variable "frts" (frts="apples;bananas;melons;pears"). This list is needed in the command and I built it here knowing the fruit names and their order. If the names and order weren't known, another command would be needed to extract them from the table and order them properly.
Also in the BEGIN statement, AWK prints the string Date; followed by the contents of the variable "frts". This gives the output a header line: Date;apples;bananas;melons;pears. Next, AWK splits "frts" and stores each fruit name in the array "a" (split(frts,a,";")).
Starting with the second line of the table (NR>1), AWK first stores "frts" in a new variable "x". It then loops through each of the fruit names (for (i in a)) and for each fruit name it loops through the fields in the table beginning with the second field (for (j=2;j<=NF;j++)). For each field AWK checks to see if a fruit name is present, as in "2 apples" (if ($j ~ a[i])). If so, AWK splits the field into pieces ("2", "apples") and stores the pieces in the array "b" (split($j,b," ")). AWK then substitutes the fruit name in the variable "x" with the number of that fruit (sub(a[i],b[1],x)).
The result is an "x" with a number where a fruit name used to be. For the second line in the table, that result is "2;6;melons;pears". AWK next deletes from "x" the non-numerical strings (gsub(/[[:alpha:]]/,"",x), giving in this case "2;6;;". Finally, AWK prints the date from field 1 and the new version of "x" (print $1";"x): "2024-09-01;2;6;;". The variable "x" is regenerated as "frts" on each succeeding line.
Work with "fruits" as-is. One solution uses AWK and sed, but there's a caution in it:
awk -F"[;,]" 'BEGIN {PROCINFO["sorted_in"]="@ind_str_asc"} \
NR>1 {for (i=2;i<=NF;i++) \
{split($i,a," "); b[a[2]]+=a[1]}} \
END {for (j in b) printf("%s %s, ",b[j],j); print ""}' fruits \
| sed 's/, $//'

This solution uses a "nested" array (array of an array). AWK is first told that the field separator in "fruits" is either a semicolon or a comma (-F"[;,]"). See CAUTION below about the BEGIN statement.
Moving to the second line (NR>1), AWK loops through each field from the second one (for (i=2;i<=NF;i++)). In each field it splits the contents into the number of fruit pieces and the fruit name and stores them in the array "a" (split($i,a," ")). AWK then build a new array "b" whose index string is the fruit name from "a" (a[2]) and whose value string is incremented with the number of fruit pieces (+=a[1]).
In the END statement after all lines have been processed this way, AWK loops through the array "b" (for (j in b)) and prints the total number of fruit pieces (b[j]), a space, the fruit name (j), a comma and a space (printf("%s %s, ",b[j],j). AWK then prints a newline (print "") and exits.
A final sed command tidies the result by deleting the final comma and space (sed 's/, $//').
CAUTION. Notice that the output is in alphabetical order, because the BEGIN statement instructs AWK to sort the array "b" in alphabetical order by index string (fruit name) (see this BASHing data post for an explanation). Without this instruction, the order of items when the array "b" is looped-through is undetermined and may not be alphabetical. More on this issue in an upcoming BASHing data 2 post...
Last update: 2024-09-20
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License