
For a list of BASHing data 2 blog posts see the index page. ![]()
How to detect and convert those baffling ruffians
Look carefully at the words "baffling ruffians". Do they seem OK to you, or is there something a little strange about them?
That will depend on the font you've selected for your browser. Here's how the words look in several fonts in LibreOffice Writer:

What you're seeing in "baffling" isn't the characters "f", "f" and "l" somehow pushed close together, but a separate, special character called "Latin small ligature ffl", Unicode U+FB04. There are 7 of these odd characters in Unicode's Latin ligatures block:
ff U+FB00 latin small ligature ff
fi U+FB01 latin small ligature fi
fl U+FB02 latin small ligature fl
ffi U+FB03 latin small ligature ffi
ffl U+FB04 latin small ligature ffl
ſt U+FB05 latin small ligature long st
st U+FB06 latin small ligature st
The Unicode folk don't think warmly of these characters:
The existing ligatures, such as "fi", "fl", and even "st", exist basically for compatibility and round-tripping with non-Unicode character sets. Their use is discouraged. No more will be encoded in any circumstances.
and there's usually no good reason for their use in data text. Nevertheless, I sometimes see them in my data auditing. In a locality field in a museum database, I found (among other examples):

The 7 ligature characters can be spotted in the output of the graphu script, and each can be highlighted in TSV data tables plus their record ID and field with the charfindID function:
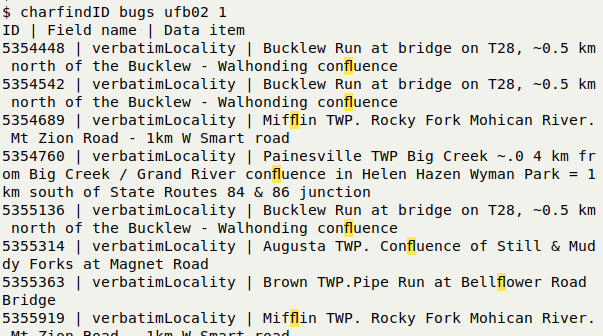
More simply, with grep you can count lines having the ligature characters, isolate the characters or total them up for a file:
2-line "demo" file:
Baffling ruffians lost in a moſtly daffodil flower field
Baffling ruffians lost in a mostly daffodil flower field
grep -cP "[\x{fb00}-\x{fb06}]" demo
grep -oP "[\x{fb00}-\x{fb06}]" demo
grep -oP "[\x{fb00}-\x{fb06}]" demo | wc -l

To retrieve whole words containing ligature characters I use GNU AWK:
awk $'{for (i=1;i<=NF;i++) if ($i ~ /[\ufb00-\ufb06]/) print $i}' demo
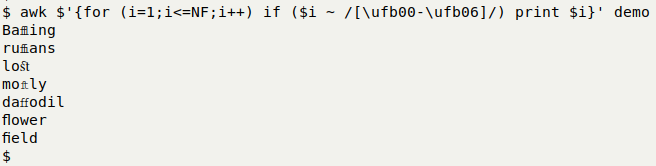
Note the "$" in front of the AWK command, which allows the shell to interpret the escaped characters \uNNNN. Whole words are returned because the default field separator for AWK is a space or series of spaces.
I convert files with these ligature characters to their ASCII equivalents ("ASCII-fication"?) with an AWK function, "delig":
delig() { awk $'FNR==NR {a[$1]=$2; next} /[\ufb00-\ufb06]/ {for (i=1;i<=NF;i++) if ($i ~ /[\ufb00-\ufb06]/) sub($i,a[$i])} !(/[\ufb00-\ufb06]/) {print}' ~/scripts/ligs FS="" "$1"; }
AWK first builds an array from a file in my scripts folder called "ligs", which looks like this:
ff ff
fi fi
fl fl
ffi ffi
ffl ffl
ſt st
st st
The array is indexed with the 7 ligature characters, and the value string for each is the ASCII equivalent. These are separated by spaces, which are the default field separators for AWK.
Moving on to the file to be "deligged", AWK checks to see if the line contains one of the 7 ligature characters. If not (!(/[\ufb00-\ufb06]/)), the line is printed.
If one or more of the characters is found, AWK now moves through the line character-by-character (for (i=1;i<=NF;i++)) because the field separator for the file has been set to the null string as a pseudo-argument before the file to be "deligged" (FS="").
If a character is tested and found to be one of the ligature characters, it's replaced from the array (sub($i,a[$i])) and the line is printed.
Below, "delig" is applied to the "Baffling ruffians" demo file, and also to a selection of lines from the locality field in the file "bugs":


Last update: 2024-06-28
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License