
For a list of BASHing data 2 blog posts see the index page. ![]()
Minimum, maximum and range by group
Given the following file ("file")
group value
b 19
d 20
a 10
a 52
b 80
c 85
b 39
c 22
c 22
c 29
a 83
d 93
how easy is it to get min, max and range by group?
Answer: easy, with GNU datamash:

tail -n +2 file | sort | datamash -t" " -g1 min 2 max 2 range 2
Remove the "file" header with tail and sort the headless file by group, then pass the output to datamash with the -t" " option to specify that the field separator is a space. datamash then groups by field 1 (-g1) and finds the minimum value in field 2 (min 2), the maximum value (max 2) and the range between the minimum and maximum (range 2).
Answer: not so easy with AWK, and there's a gotcha.
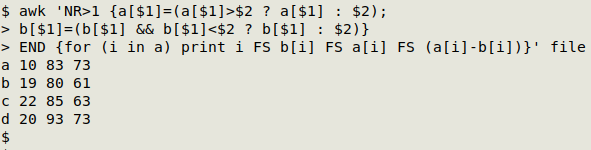
awk 'NR>1 {a[$1]=(a[$1]>$2 ? a[$1] : $2); b[$1]=(b[$1] && b[$1]<$2 ? b[$1] : $2)} END {for (i in a) print i FS b[i] FS a[i] FS (a[i]-b[i])}' file
Skip the header (NR>1). The strategy here is to build a maximum array ("a") with "group" as the array index value and "value" as the array value, do the same for a minimum array ("b") and get the range by calculating the difference.
The maximum array is built with a[$1]=(a[$1]>$2 ? a[$1] : $2), which translates as Is the existing value of "a" for that index larger than the entry in field 2? If so, the array value doesn't change. If the entry in field 2 is larger than the existing array value, then replace that value with the field 2 entry. For the first line the array value doesn't exist yet, so the array value becomes the field 2 entry.
The gotcha comes when doing the same test for a minimum. In this case a "b" array value must already exist for the test to work, so the condition includes that as b[$1] && b[$1]<$2. Note that a space is AWK's default field separator.
AWK helped me a lot, though, in a recent data analysis. I wanted records organised and sorted by range and group, with all the minimum and maximum records shown. For example, if I add a unique identifier to each record in "file", making "idfile":
id group value
001 b 19
002 d 20
003 a 10
004 a 52
005 b 80
006 c 85
007 b 39
008 c 22
009 c 22
010 c 29
011 a 83
012 d 93
then the output I'd like would be this, in descending order of range size:
73 003 a 10
73 011 a 83
73 002 d 20
73 012 d 93
63 008 c 22
63 009 c 22
63 006 c 85
61 001 b 19
61 005 b 80
I might be able to get this result by complicating that already complicated AWK command above, but I decided it would be easier to start with the output from datamash:
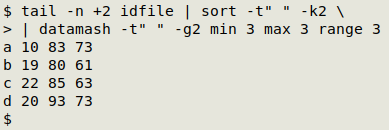
tail -n +2 idfile | sort -t" " -k2 | datamash -t" " -g2 min 3 max 3 range 3
I passed the datamash output through several commands. The first one uses AWK to do the heavy lifting, namely printing minimum and maximum records by group and prefixing each record with the range found in that group:
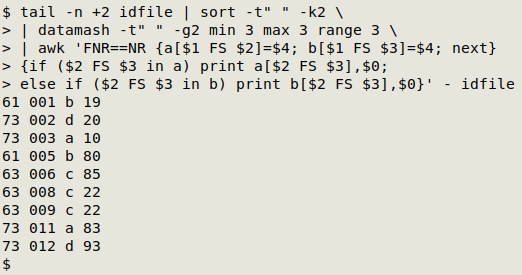
awk 'FNR==NR {a[$1 FS $2]=$4; b[$1 FS $3]=$4; next} {if ($2 FS $3 in a) print a[$2 FS $3],$0; else if ($2 FS $3 in b) print b[$2 FS $3],$0}' - idfile
The command takes the datamash output (as stdin, "-") and builds two arrays with it. The first ("a") takes the group and minimum value as array index, and the range as array value. The second ("b") does the same with the maximum value.
AWK now moves on ("next") to "idfile" and works through the file line by line. If the group and value are the same as the group and value in the "a" index set, AWK prints the range (the array value), a space and the whole line. Alternatively, if the group and value are the same as the group and value in the "b" index set, AWK prints the range (the array value), a space and the whole line.
All that's left to do is to sort the AWK output by range, group and value, and separate the record sets that have the same range and group. I can do the sorting with GNU sort:
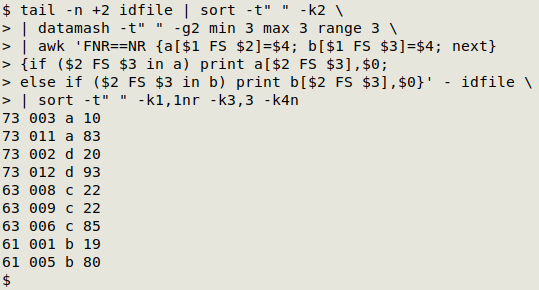
sort -t" " -k1,1nr -k3,3 -k4n
Because the output is now sorted on field 1, I can use an AWK trick to space out the sets with the same range:
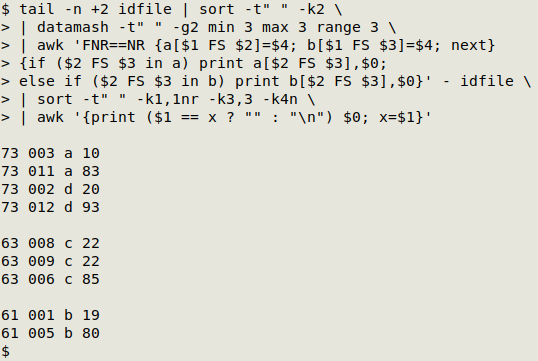
awk '{print ($1 == x ? "" : "\n") $0; x=$1}'
At the first line, AWK checks to see if the first field (range) value is "x". Since "x" hasn't yet be defined, AWK prints a newline and follows that with the whole first line. It then defines "x" as the value in field 1.
At the second line, the field 1 value is indeed "x", so AWK prints nothing ("") followed by the whole second line. The same happens at lines 3 and 4.
At line 5, the field 1 value has changed and isn't "x", so AWK again prints a newline and follows it with the whole fifth line.
And so on... This is a particularly neat way to space out lines based on field content, but it requires that the chosen field is sorted.
Finally, to separate the groups with the same range value (73 in this case) but different groups, I can use that AWK trick again, following it with cat -s to squeeze multiple blank lines into one:
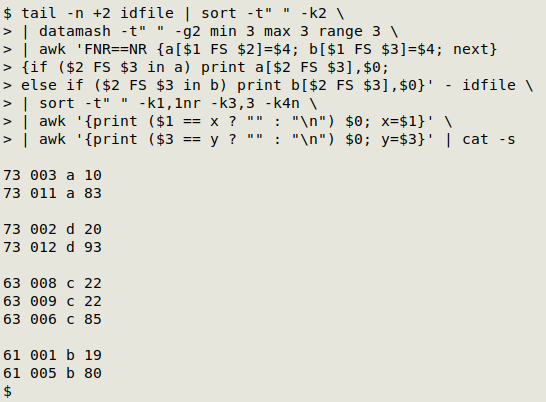
awk '{print ($3 == y ? "" : "\n") $0; y=$3}' | cat -s
The real-world analysis I did was on a TSV where the group was the 2 fields latitude and longitude, combined, and the value field was elevation. There might be various reasons for points with exactly the same lat/lon to have slightly different recorded elevations (it depends on the elevation's base level and the method used to determine the elevation), but if there's a lat/lon with records having vastly different elevations, like 100 meters or more, then something's wrong.
The screenshot below shows some of the results. I've replaced tab characters with [space][pipe][space] for clarity, and I didn't sort the elevation field after sorting by range and group. Field 1 is the range in meters, field 2 is the record ID (a UUIDv4), fields 3 and 4 are the original latitude and longitude, field 5 is the elevation and fields 6 and 7 are the lat/lons rounded to 4 decimal places. These pairs need checking!

Last update: 2024-05-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License