
For a list of BASHing data 2 blog posts see the index page. ![]()
GNU datamash and months
GNU datamash is a wonderful tool for command-line data analysis, but it needs help with some operations. One of those operations is sorting by month.
This CSV ("file") has costs by agent and month:
Name,Month,Cost
Lee,Jan,154.18
Ray,Jan,272.87
Lee,Feb,170.91
Ray,Feb,148.60
Lee,Mar,256.20
Ray,Mar,42.10
Lee,Apr,150.78
Ray,Apr,79.76
Lee,May,16.92
Ray,May,16.91
Lee,Jun,230.86
Ray,Jun,273.58
Lee,Jul,196.51
Ray,Jul,325.32
Lee,Aug,312.12
Ray,Aug,205.03
Lee,Sep,179.71
Ray,Sep,319.82
Lee,Oct,149.72
Ray,Oct,15.77
Lee,Nov,119.23
Ray,Nov,14.12
Lee,Dec,28.90
Ray,Dec,137.49
If I build a pivot table with datamash, the months are sorted in alphabetical order:
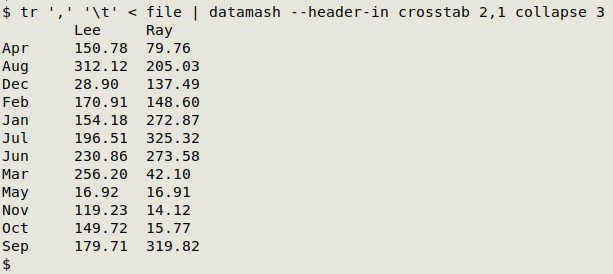
tr converts the CSV to a tab-separated file. The "--header-in" option for datamash removes the field names, "crosstab 2,1" pivots the table using field 2 for the first column and field 1 for the row header, and "collapse" returns the items in field 3 as-is.
But that's easily fixed with GNU sort's "-M" option:
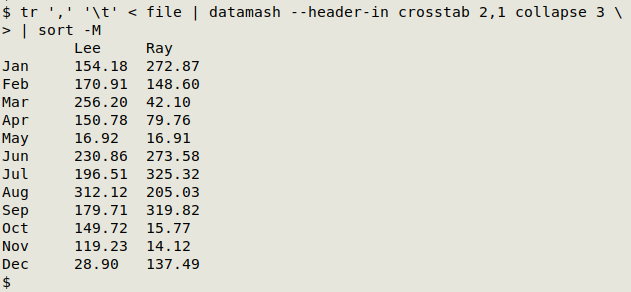
The sort-by-month "-M" option for GNU sort works for the various orthographic variants I've tried for the months in English, but I don't know about months in other languages - that might require a temporary change in locale setting if you're working in an English-language locale.
And I can build the table the other way around with datamash transpose:

What if the data are in Australian financial year order, July to June, as in "fy-file", below?
Name,Month,Cost
Lee,Jul,196.51
Ray,Jul,325.32
Lee,Aug,312.12
Ray,Aug,205.03
Lee,Sep,179.71
Ray,Sep,319.82
Lee,Oct,149.72
Ray,Oct,15.77
Lee,Nov,119.23
Ray,Nov,14.12
Lee,Dec,28.90
Ray,Dec,137.49
Lee,Jan,154.18
Ray,Jan,272.87
Lee,Feb,170.91
Ray,Feb,148.60
Lee,Mar,256.20
Ray,Mar,42.10
Lee,Apr,150.78
Ray,Apr,79.76
Lee,May,16.92
Ray,May,16.91
Lee,Jun,230.86
Ray,Jun,273.58
A fairly ugly hack could use head and tail to re-order the months sorted by sort -M:
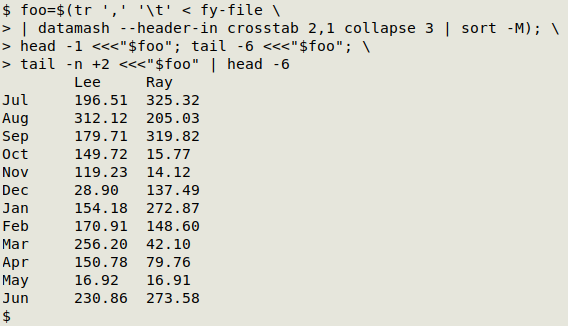
Here's a slightly more elegant method. It works on the alphabetically sorted months from the datamash output:
tr ',' '\t' < fy-file | datamash --header-in crosstab 2,1 collapse 3 | awk 'BEGIN {split("Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May Jun",a)} NR==1 {print} NR>1 {b[$1]=$0} END {for (i in a) print b[a[i]]}'
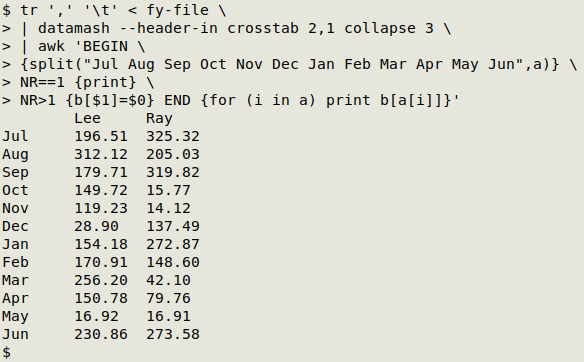
The AWK command begins by ordering the months from July through June in an array "a" built with AWK's split function. In this array the index strings are the numbers 1 to 12, i.e. "Jul" is indexed with 1, "Aug" with 2, and so on. After the header line is printed, AWK builds a new array "b" containing each of the month/cost lines indexed by month. In the END statement these are printed out in the numerical order from the "a" array.
Last update: 2024-02-16
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License