
For a full list of BASHing data blog posts see the index page.
People are the best data cleaners
Did you raise your eyebrow skeptically when you read the title of this blog post?
If you did, maybe you're a penny-pinching manager in a business or government agency. "People are expensive. Isn't there some off-the-shelf software or online service that can clean our data automatically?"
Or you might be an ambitious developer. "If people can do it, software can do it. And data's just text, for Heaven's sake. How hard could it be to write a text-cleaning package?"
Or you might be a machine-learning specialist, confident that after just a few hundred hours of training with the right sort of datasets, your pet ML project could become the Leela Chess Zero or GNMT of data cleaning.
Readers who agree with the title of this post are likely to be a bit closer to the realities of data cleaning than my hypothetical manager, developer and ML enthusiast.
No, there isn't a Rinso for dirty data.
Yes, text cleaning can be formidably difficult.
And maybe a deep neural network can (in future) tidy a dataset nearly as well as a data professional. But a machine learning construct can't sit down with the data provider afterwards, explain in simple terms why the dataset is a mess, and discuss ways to prevent messiness in future.
OK, so who cleans data well in the real world, and how do they do it?
The second question is easier to answer than the first. The graphic below is by Jeroen Janssens, data science consultant and author of the excellent Data Science at the Command Line, now in its second edition. (The blue "spreadsheet" label is an edit by me of Janssens' original.)
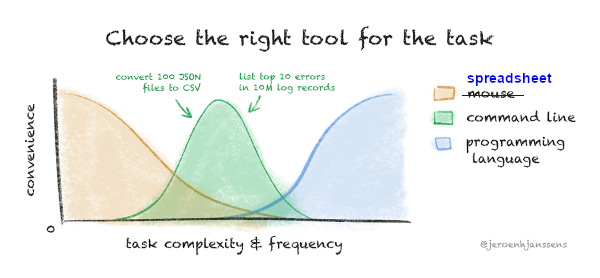
At the low end of Janssens' complexity and frequency graph, spreadsheet programs like Microsoft's Excel are fine for cleaning tabular data. Excel users can apply filters and validation rules, and with practice can become very good at eyeballing problems in a dataset.
As the dataset gets larger or the checking and cleaning job gets harder, command-line tools come into their own. I won't say too much about tasks of this kind, as they're covered in A Data Cleaner's Cookbook and many of the earlier posts on this blog. This is the domain of DIY data checking with AWK and GNU/Linux shell tools. What you do and how you do it will depend on the nature of the dataset, and you will probably need to modify your commands as cleaning progresses. Although there are no upper limits here to dataset size, I suspect that 10 million records and a few hundred fields will test your patience. (Start job, go make coffee, drink coffee, check if job has finished running...)
At the top end of Janssens' graph are jobs involving enormous datasets, complex analysis and high-end visualisations. Python and R are the popular choices here. Both languages have libraries and methods for cleaning data, i.e. for getting data ready to be analysed. However, if you can separate the cleaning and analysis parts of a task, you may find (as I've argued before) that it's easier to do the cleaning with shell tools before you enter the Python or R environment.
So, who cleans data well? People with a careful bookkeeper's attention to correctness, completeness and consistency. People whose mental alarm bells start ringing when they see ambiguous or badly formatted data. People who expect data to be tidy, and who are disappointed when it isn't.
Since these are personality traits and lifelong habits, not everyone who's been lured into "data science" in recent years is a competent data cleaner. I put "data science" in quotes because I'm referring to the corporate version, which is the study of how to use data analytics better than the competition and squeeze more money out of customers.
A good source of data cleaners is the pool of recent graduates in Library and Information Science. There is a truly unfortunate prejudice against librarians in the data-based professions, a prejudice based on obsolete stereotypes: bespectacled women stamping book cards in the local branch library. Today's librarians are information management professionals. From the Wikipedia article on the Master of Library and Information Science degree:
The "Information Science" component of the degree is composed of the acquisition of technology skills similar to those found in a computer science or related degree program. Courses in the program that focus on information science and computer science include: data science, data analytics, and data management; institutional repository management; digital libraries and digital preservation; information systems and information architecture; networking hardware and software skills required to manage a computer network; integrated library systems utilizing relational databases and database design; mastery of multiple computer programming languages; web design, metadata and semantic web technologies; automation and natural language processing (NLP); informatics; as well as taxonomy (general), and ontology (information science).
I won't go so far as to say that librarians are the best data cleaners, but if you're hiring, look for an LIS background.
This is the 200th and last BASHing data blog post. All 200 posts and A Data Cleaner's Cookbook will remain online, and you can download the lot as a single ZIP archive from Zenodo.
I've enjoyed writing this blog over the past four years and I hope command-line users have found it helpful. If I could condense the Cookbook and the blog into a single piece of advice for data workers, it's this: learn AWK.
Last update: 2022-04-08
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License