
For a full list of BASHing data blog posts see the index page. ![]()
Search for (exact) strings; report line, column and context
GNU grep is a great utility but it can only report a search target's line number. Suppose I search for the string "64" in this tab-separated "demo" table with grep's "-n" option:
| Fld1 | Fld2 | Fld3 | Fld4 | Fld5 | Fld6 | Fld7 | Fld8 |
| 001 | 7b03 | 020d | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 002 | 521a | 1da1 | f9eb | 4268 | 9fa8 | fc7357 | 0a31b8 |
| 003 | e6c3 | 0e9b | dc9f | 448b | b1c4 | 7705ca | 772ab5 |
| 004 | 36cf | fd59 | 0c62 | 4eb6 | 82d1 | e30076 | ecedbd |
| 005 | 15c5 | 7874 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 006 | b3fb | 5bad | 3361 | 4259 | a5b0 | 30370c | 953333 |
| 007 | 15c5 | c3d5 | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 008 | 7b03 | 7686 | d264 | 4c34 | b0e4 | 364607 | 5af668 |
| 009 | 7ee1 | 8a53 | 5cc5 | 4f57 | 9cf5 | ddc735 | 56eee8 |
| 010 | bd75 | 3324 | 21mz | 41b0 | b1bc | 22964a | b9f2a3 |
| 011 | 15d7 | 1fb2 | 7223 | 4e8f | 8f1f | 8e6b76 | f60cd1 |
| 012 | c3cc | ef6c | 70fb | 4a45 | 9428 | f00f73 | 07e92d |
| 013 | 9ab4 | 991c | 0bd7 | 4f3c | badf | ee145b | 5a6d17 |
| 014 | 6ad5 | 8395 | 19aa | 43c4 | 9cea | 3a3c90 | e84150 |
| 015 | 607c | 3753 | 8a69 | 44bf | b41f | ddb1eb | 4a42ff |
| 016 | 7b03 | f067 | 71b7 | 43c4 | 8ffd | f9352b | 102e2d |
| 017 | 05f1 | 89f3 | 5067 | 6712 | b1c4 | 3b5245 | 4c4e35 |
| 018 | e20d | 5346 | 71a8 | 4b26 | a31d | ab914d | e39049 |
| 019 | 15c5 | 52bd | 33dc | 4b20 | b1c4 | 7a1f3b | 8465b0 |
| 020 | e917 | b879 | 08dd | 4387 | b520 | 814a8a | 10717b |

OK, "64" appears on lines 9 and 11, but grep has left it up to me to figure out which fields contain "64". Because field location is often important in my data work, I wrote a function ("fldgrep") that searches for an exact string and returns the string's line and field location (field number and field name) plus the data item containing the string, with the string coloured red:
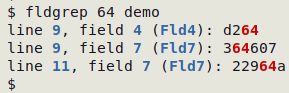
The function "fldgrep" is actually a single AWK command, although fairly complicated, that works on tab-separated data tables:
fldgrep() { awk -F"\t" -v target="$1" -v blue="\x1b[1;34m" -v red="\x1b[1;31m" -v reset="\x1b[0m" 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i} NR>1 {for (j=1;j<=NF;j++) if ($j ~ target) {n=split($j,m,target,sep); printf("%s","line " blue NR reset ", field " blue j reset " (" blue a[j] reset "): "); for (k=1;k<=n;k++) printf("%s", m[k] red sep[k] reset); print ""}}' "$2"; }
"fldgrep" is explained in the next section. Below are a couple of examples of "fldgrep" in use.
Multiple appearances on one line:
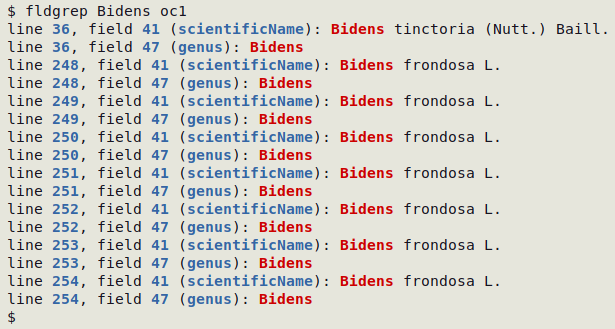
Multiple appearances in one field:
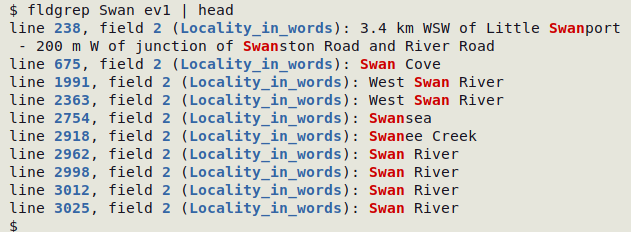
awk -F"\t"
Invokes AWK and tells it that the field separator is the tab character
-v target="$1"
Assigns the first argument of the function (the target string) to the AWK variable "target"
-v blue="\x1b[1;34m"
Assigns the ANSI color escape for bold blue to the AWK variable "blue"
-v red="\x1b[1;31m"
Assigns the ANSI color escape for bold red to the AWK variable "red"
-v reset="\x1b[0m"
Assigns the ANSI color escape for no coloring to the AWK variable "reset"
NR==1
Tells AWK to do a particular action with the table's header line
for (i=1;i<=NF;i++)
The action with the header line is to loop through each of the fields, and
a[i]=$i
add each entry in the header line to an array "a" with the field number as index string and the field contents as value string
NR>1
The remaining actions in the command get done line by line after the header line
for (j=1;j<=NF;j++)
Loop through each of the fields in the line
if ($j ~ target)
Check if the target string is part of the entry in that field, and if yes, do the following four actions
n=split($j,m,target,sep)
The first action is to split the field using the target string as the separator. Put the non-target strings in the array "m" and the adjacent separator (target) in the array "sep". Tally up the number of non-target strings in the variable "n"
printf("%s","line " blue NR reset ", field " blue j reset " (" blue a[j] reset "): ")
The second action (for each field containing the target string) begins with printfing some text (see screenshots above) with the line number, field number and field name highlighted in blue
for (k=1;k<=n;k++)
The third action begins by looping through the non-target strings found by split
printf("%s", m[k] red sep[k] reset)
For each of the non-target strings, printf the non-target string and the red-highlighted target string
print ""
The last action for each field containing the target string is to print nothing and move to the next line
"$2"
This is the second argument for the function, and is the name of the file on which AWK is operating
Last update: 2022-03-09
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License