
For a full list of BASHing data blog posts see the index page. ![]()
Online shopping and a one2many tweak
Online commerce sites often show a selection of items below the one you're after, with a caption something like "People who bought this item also bought..." It's a marketing ploy, the aim being to encourage you to buy something else while you're visiting the site. It also suggests an interesting question: what product combinations are bought most and least frequently by individual shoppers?
This may have been the question lurking behind a Stack Overflow post from 2017. Given this CSV ("demo") of customers and purchases:
customer,package
a,pack1
a,pack2
b,pack1
c,pack1
c,pack2
d,pack3
d,pack2
d,pack1
e,pack1
e,pack3
f,pack1
f,pack2
f,pack3
the OP wanted to know how many unique customers bought each of the combinations of packages.
The answer can be found quickly if the data are first reorganised by customer, like this:
a:pack1,pack2
b:pack1
c:pack1,pack2
d:pack1,pack2,pack3
e:pack1,pack3
f:pack1,pack2,pack3
All you have to do next is cut out the product field and sort, uniquify and count the data items:

But how to get that by-customer arrangement of product combinations?
Either GNU datamash or AWK will do the job. In both cases I'd start by tailing off the unneeded header, then sorting the "package" field. The datamash approach:
tail -n +2 demo | sort -t"," -k2 \
| datamash -st"," --output-delimiter=":" groupby 1 unique 2
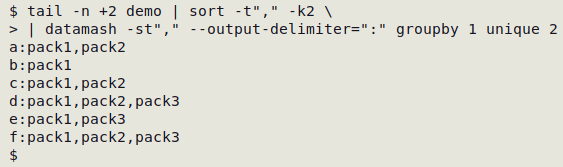
The input data are sorted and the field separator specified with -st",". datamash is then instructed to build a comma-separated list of unique values in field 2 (unique 2) for each of the unique values in field 1 (groupby 1), and to separate the output fields with a colon (--output-delimiter=":").
With AWK:
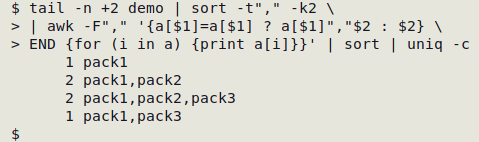
tail -n +2 demo | sort -t"," -k2 \
| awk -F"," '{a[$1]=a[$1] ? a[$1]","$2 : $2} \
END {for (i in a) {print i":"a[i]}}'

AWK is told that the field separator is a comma with -F",". What happens next is a little cryptic. An array "a" is built with field 1 as the index string (a[$1]). The value string corresponding to that index string changes as the file is processed. The ternary construction a[$1] ? a[$1]","$2 : $2 after a[$1]= in plain English is Does that index string already exist in the array? If so, its value string is whatever is there already, followed by a comma, followed by the current line's field 2. If the index string doesn't already appear in the array, then its value string equals the current line's field 2.
After the file is processed, the END statement tells AWK to print each index string in turn, followed by a colon, followed by the final value string for that index string.
If you're not interested in the by-customer result and only want to know the frequencies of product combinations, you can avoid cutting out the second field after the colon by having AWK just print the array contents:
tail -n +2 demo | sort -t"," -k2 \
| awk -F"," '{a[$1]=a[$1] ? a[$1]","$2 : $2} \
END {for (i in a) {print a[i]}}' | sort | uniq -c
Tweaking the one2many commands. Following a suggestion from Maxim Shashkov, I've modified the one2many group of commands in A Data Cleaner's Cookbook so that sets of similar items are separated by a blank line. These screenshots show the difference:
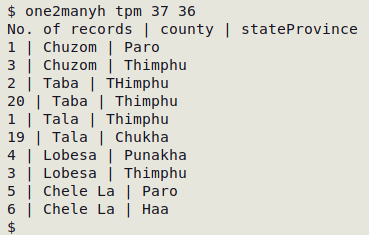
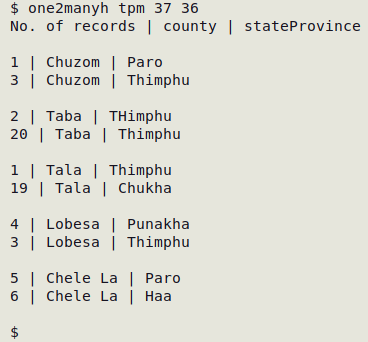
The code difference is shown below for one2many. I've added print RS to the AWK command so that a blank line is added after every step in the inner for loop. That can generate a lot of blank lines, but cat -s squeezes multiple blank lines to a single blank line.
one2many() { awk -F"\t" -v one="$2" -v many="$3" '$one != "" {a[$one]++; b[$one][$many]++} END {for (i in b) {for (j in b[i]) {if (a[i]>b[i][j]) print b[i][j] FS i FS j}}}' "$1"; }
one2many() { awk -F"\t" -v one="$2" -v many="$3" '$one != "" {a[$one]++; b[$one][$many]++} END {for (i in b) {for (j in b[i]) {if (a[i]>b[i][j]) print b[i][j] FS i FS j} print RS}}' "$1" | cat -s; }
Last update: 2022-02-23
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License