
For a full list of BASHing data blog posts see the index page. ![]()
"Firstname Lastname" to "Lastname, Firstname", with complications
This particular reformatting task is one I've seen celebrated as easy-peasy with AWK. Do you want "Firstname Lastname" made into "Lastname, Firstname"? No problem:
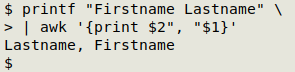
In the real world, the job isn't usually that simple. Take this tab-separated table, for example, called "demo1":
| Fld1 | Fld2 | Fld3 |
| 001 | Fred Bloggs; Diane Carberry | 2021-03-05 |
| 002 | Diane Carberry | 2021-03-05 |
| 003 | D. Carberry; F. Bloggs; A.R. Frumious | 2021-03-06 |
The table is simplified from a real one I was re-building (with thousands of rows). The names had to be formatted with a space, a pipe and a space between them, like this:
Lastname, Firstname | Lastname, Firstname
So I did:
awk -F"\t" 'NR==1 {print} NR>1 {printf("%s\t",$1); n=split($2,a,";"); for (i=1;i<=n;i++) {split(a[i],b," "); if (i<n) printf("%s, %s | ",b[2],b[1]); else printf("%s, %s",b[2],b[1])}; printf("\t%s\n",$3)}' demo1
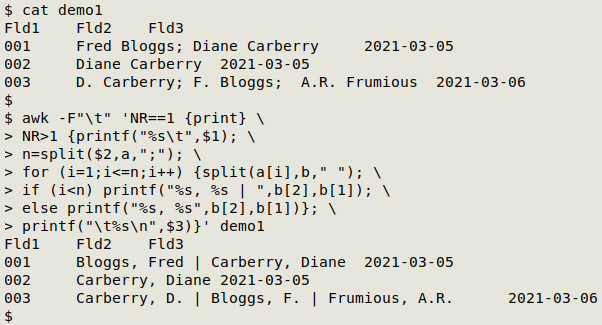
AWK is first told with -F"\t" that "demo1" is tab-separated. The first action ({print}) just prints the header line (NR==1).
For all subsequent lines (NR>1) there's a series of actions to be carried out. The first is to print field 1 followed by a tab, but with no newline (printf("%s\t",$1)). Now to deal with the names-containing field, field 2...
n=split($2,a,";") splits field 2 into pieces based on the separator ";" and puts each piece into the array "a". The total number of pieces is stored in the variable "n". If there's no ";" in field 2, the whole data item is stored in a[1] and "n" equals one.
Note that splitting on ";" means that some pieces will have a leading space. For example, record 001 will have "Fred Bloggs" in a[1] and " Diane Carberry" in a[2]. The leading spaces will disappear shortly when split is used again (see below).
AWK now starts a for loop that works through each of the data items stored in "a", from a[1] to a[n] (for (i=1;i<=n;i++)). Each piece in "a" is further split, this time with a space as separator (split(a[i],b," ")) and the pieces (parts of names) are stored in the array "b".
Next there's an if/else construction that counts the number of pieces in "n". For lines where the number of names was bigger than one (if (i<n); records 001 and 003), AWK prints the split pieces of the first name or names (not including the "nth" name), formatting them as "lastname, firstname" followed by a space, a pipe and a space, with no newline (printf("%s, %s | ",b[2],b[1])).
For lines where there was only one name (record 002) and for the last name in multi-name data items (else), AWK prints "lastname, firstname", again with no newline (printf("%s, %s",b[2],b[1])).
Finally, AWK prints a tab, the third field and a newline (printf("\t%s\n",$3)), thus finishing the processing of the line.
What happened to the leading spaces in those multi-name lines? They disappeared because the second split used a space as separator (split(a[i],b," ")), and as the GNU AWK manual says, "...when the value of fieldsep [the separator] is " ", leading and trailing whitespace is ignored in values assigned to the elements of array...
What if there were names like "Frederick George Bloggs" that you wanted to reformat to "Bloggs, Frederick George"? Or "Manuela Lopez Morales" to "Lopez Morales, Manuela"? "Dirk van de Berg" to "van de Berg, Dirk"? My brain hurts just thinking about that. Name parsing is difficult, and I'm glad I only had two-component names to reformat!
Last update: 2021-06-23
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License