
For a full list of BASHing data blog posts see the index page. ![]()
Comparing strings more clearly
In a recent data audit, field 19 of a TSV contained a scientific name, and field 20 contained another version of the name plus the scientific authority for that name. In most cases the two name versions were the same, like this:
Anadyomene stellata Anadyomene stellata (Wulfen) C.Agardh
In other cases the two versions weren't the same. Sometimes the species or subspecies names differed, sometimes the genus names and sometimes both:
Ceramium fastigiatum Ceramium cimbricum H.E.Petersen
Codium fragile subsp. tomentosoides
Codium fragile subsp. fragile (Suringar) Hariot
Boergeseniella thuyoides Vertebrata thuyoides (Harvey) Kuntze
Acrosorium uncinatum Cryptopleura ramosa (Hudson) L.Newton
I used AWK to select out the field 19/field 20 pairs where the names differed. To demonstrate this command I'll use a simplified TSV called "demo", with fake scientific names:
| ID | Name | Alt_name+authority |
| 001 | Primium vulgare | Secundum vulgare Müller |
| 002 | Primium | Primium De Blas |
| 003 | Trivius latum scotensis | Trivius latus scotensis Baker |
| 004 | Primia | Primium De Blas |
| 005 | Secundum vulgare | Secundum vulgare Müller |
| 006 | Primia vulgaris | Secundum vulgare Müller |
| 007 | Trivius latus scotensis | Trivius latus scotensis Baker |
| 008 | Primium latum scotense | Trivius latus scotensis Baker |
awk -F"\t" 'NR>1 {n=split($2,a," "); split($3,b," "); \
for (i=1;i<=n;i++) if (a[i] != b[i]) {print; next}}' demo
Core parts of this command are explained below.

AWK users may be wondering why I didn't just test the longer field to see if it matched the shorter field, like this: $3 !~ $2. That's OK for strings with only alphanumeric charcters, but the matching will throw fatal errors if the shorter string contains something that looks like an invalid range expression or an incompletely round-bracketed one. It will also return a non-match if the shorter field contains "*". The command I used is longer but safer.
This worked fine, but it didn't tell me which of the names were different. A bit of tinkering with AWK led me to a nice couple of solutions. The first method selects the lines with name changes and colorises the "before" and "after" words:
awk -F"\t" 'NR>1 {n=split($2,a," "); split($3,b," "); \
for (i=1;i<=n;i++) {if (a[i] != b[i]) \
{sub(a[i],"\033[1;31m"a[i]"\033[0m",$2); \
sub(b[i],"\033[1;31m"b[i]"\033[0m",$3)}}} /\033/' \
OFS=" | " demo
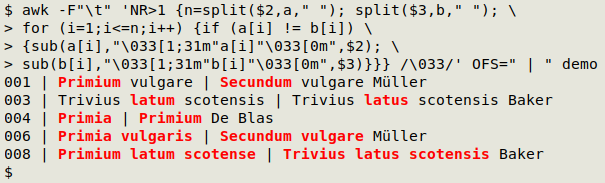
There are two condition-action parts to the command. The main one (inside the 3 nested curly brackets) has NR>1 its condition, so it only applies to lines after the header.
The main action begins by splitting fields 2 and 3 into arrays "a" and "b", respectively. Each array element will contain a space-separated word. In addition, the total number of words in field 2 is counted and stored in the variable "n". (Besides splitting strings, split also returns the number of array elements it creates.)
The main action now starts a for loop which iterates the variable "i" through "n" (for (i=1;i<=n;i++)). In other words, what happens next will only happen for the words in field 2, and any additional words in field 3 will be ignored.
For each word in field 2, AWK checks to see if it differs from its corresponding word in field 3 (if (a[i] != b[i])). If that's true, then AWK substitutes a colorised version of the word, in both fields. The substitution is done with the sub function and uses ANSI color escapes for the colorising (e.g. sub(a[i],"\033[1;31m"a[i]"\033[0m",$2))
With all those jobs done, AWK turns to the second condition (/\033/). If the escape character is found in the line, the line is printed (default action).
As a final touch for clarity, AWK is told with OFS=" | " as a "pseudo-argument" that the output field separator is space, pipe, space.
This first solution shows me the differences between names if I happen to be in a terminal, but it doesn't produce something I can store in a text file. The second solution does that job:
awk -F"\t" 'NR>1 {n=split($2,a," "); split($3,b," "); \
for (i=1;i<=n;i++) if (a[i] != b[i]) \
f = (!f) ? a[i]"|"b[i] : f", "a[i]"|"b[i]} \
f {print $0 "\n " f; f=""}' demo
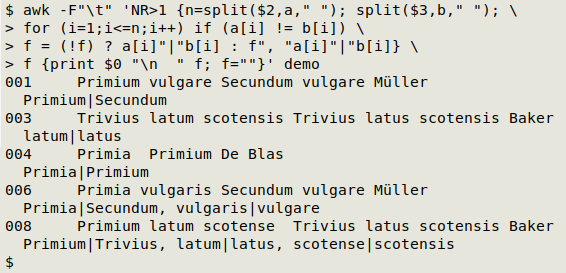
This command begins like the first one, but changes the action to be done if the words are different. The action is to define a variable "f" with a ternary "if, do this, else, do that" test. If "f" doesn't exist yet, it's defined as the field 2 word separated from its field 3 version by a pipe. If "f" does exist, it's defined as the existing "f" followed by a comma and a space, then the latest two versions separated by a pipe. That closes the action.
The second condition/action begins with the condition "f", which means "if f exists", and "f" only exists for those lines in which names differ between fields 2 and 3. The action to be taken is simply to print the whole line, a newline and a couple of spaces, then "f". After the printing, "f" is reset to an empty string in preparation for processing the next line in the file.
Last update: 2020-12-09
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License