
For a full list of BASHing data blog posts see the index page. ![]()
Re-format blah,YYYYMMDD,blah as blah,YYYY,MM,DD,blah
This exercise was inspired by a recent article by Girish Managoli. He showed how to prepare a data table for machine learning using simple shell tools.
One particular step in the data wrangling was conversion of a "concatenated" date string into its comma-separated equivalent, like this:
USR0000AALC,20100101,-220 > USR0000AALC,2010,01,01,-220
The file being prepared had lots of such lines, so a pure BASH solution wouldn't be as practical as line-by-line processing with a tool like sed or AWK. Managoli chose sed:
echo "USR0000AALC,20100101,-220" \
| sed 's/,..../&,/;s/,....,../&,/'
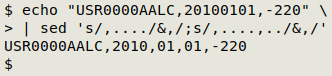
sed looks here for the first, leftmost string with a comma followed by any 4 characters, and replaces that with the same 5 characters followed by a comma. After doing that replacement, sed next looks for the first, leftmost occurrence of a comma, any 4 characters, a comma and any 2 characters, and replaces that match with the same string followed by a comma.
Below are 6 other ways to do the same job: one with sed and 5 with AWK. The last method may surprise regular AWK users.
sed
echo "USR0000AALC,20100101,-220" \
| sed -E 's/(,[0-9]{4})([0-9]{2})([0-9]{2},)/\1,\2,\3/'

Here I specify the date string as a comma, 4 numbers, 2 numbers, 2 numbers and a comma, again as the first, leftmost occurrence. The numerical components (with bounding commas) are each put within parentheses, then replaced by their backreferences separated by commas. The -E option means that the parentheses don't have to be escaped (and that sed can understand extended regular expressions).
AWK with substr. This method, like the next 3 AWK commands, involves re-building the date field, which is field 2 in the comma-separated string. Because the field is re-built, I also need to specify the output field separator, and I've done that in all 4 cases with a BEGIN statement that defines both the input and output field separators.
echo "USR0000AALC,20100101,-220" \
| awk 'BEGIN {FS=OFS=","} \
{$2=substr($2,1,4)","substr($2,5,2)","substr($2,7,2); print}'
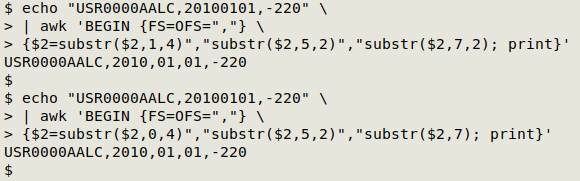
The year, month and day pieces are separately printed by breaking the date string with substr, then printing the pieces with commas between. The 3 substr arguments are target string (field 2 in this case), starting character and length of substring.
The second command in the screenshot demonstrates a couple of flexibilities in substr. The starting character can be either "1" or "0" when you begin with the left-hand end of the string, so substr($2,1,4) is the same as substr($2,0,4). Further, when you omit the length of the substring, you're telling AWK to select all characters to the end of the target string; substr($2,7,2) is the same as substr($2,7) in this case.
AWK with gensub
echo "USR0000AALC,20100101,-220" \
| awk 'BEGIN {FS=OFS=","} \
{$2=gensub(/(.{4})(.{2})(.{2})/,"\\1,\\2,\\3",1,$2); print}'

gensub takes 4 arguments: regex (or string constant) to be searched for in target string, replacement string, replacement method and target string (here, field 2). The regex is 4 characters followed by 2 characters followed by 2 characters (all of field 2), with those components each enclosed in parentheses. These are represented in the replacement string by backreferences (each escaped with a backslash) separated by commas. The method argument is 1, which means "do the replacement for the first, leftmost match in the target string"; you would get the same result with "g", meaning "do the replacement for all matches in the target string".
AWK with split
echo "USR0000AALC,20100101,-220" \
| awk 'BEGIN {FS=OFS=","} \
{split($2,a,""); $2=a[1]a[2]a[3]a[4]","a[5]a[6]","a[7]a[8]; print}'

split's arguments are the target string, an array name for the array in which the split pieces will be put, and the character to be used to split the string. Here I've defined the splitting character to be the empty string, meaning that each character in field 2 goes into a separate part of array "a": a[1] is "2", a[2] is "0" and so on. In re-defining field 2, the 8 parts of "20100101" are formatted with commas between year and month and between month and day.
AWK with date
echo "USR0000AALC,20100101,-220" \
| awk 'BEGIN {FS=OFS=","} \
{"date -d "$2" +%Y,%m,%d" |& getline foo; $2=foo; print}'

This method relies on the date command for re-formatting "20100101". It's horribly inefficient, because AWK has to call date through the shell for every line being processed in the data table. The re-formatted date string is saved in the variable "foo", and field 2 is then redefined as "foo".
AWK with FIELDWIDTHS
echo "USR0000AALC,20100101,-220" \
| awk -v FIELDWIDTHS="11 1 4 2 2 *" -v OFS="," \
'{print $1,$3,$4,$5$6}'
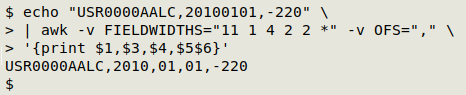
This rather odd method uses a little-known feature of GNU AWK (gawk; version 4.2 and later), namely that when specifying field widths in a space-separated string of characters, a "*" at the end means "the rest of the line". So field 1 is "USR0000AALC", field 2 is ",", field 3 is "2010", field 4 is "01", field 5 is "01" and field 6 is "everything else in the line". Fields 1, 3, 4 are printed with the output field separator, a comma, between them. Immediately following are a comma and fields 5 and 6 concatenated, because field 6 already includes the comma that separates the second "01" from "-220".
Notice that the first fieldwidth is "hard-coded" as 11 characters. What if it isn't 11? I've tried a number of ways to (a) get the number of characters in the first comma-separated field and (b) provide that number to FIELDWIDTHS, in a single AWK command. So far nothing's worked.
Last update: 2020-12-02
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License