
For a full list of BASHing data blog posts see the index page. ![]()
Join consecutive lines if condition applies
I recently looked at a TSV that had hundreds (!) of embedded newlines. Fortunately each of the "real" lines began with a serial number, and the breaks between lines were "clean" — no characters or spaces were lost or added. Below is a simplified file of this kind, "fruits". Each of the broken lines ends in a single space:
1 apple 2 pear 3 cherry, grape 4 either banana or apple or apricot 5 grape 6 watermelon, mango
The coding task is to join consecutive lines if the second (or later) line doesn't begin with a number, to get this:
1 apple
2 pear
3 cherry, grape
4 either banana or apple or apricot
5 grape
6 watermelon, mango
Two practical solutions are based either on AWK or on the all-on-one-line trick described in an earlier BASHing data post.
AWK
tail -n +2 <(awk '{if (/^[0-9]+\t/) {print m; m=$0} else {m=m$0}} END {print m}' fruits)
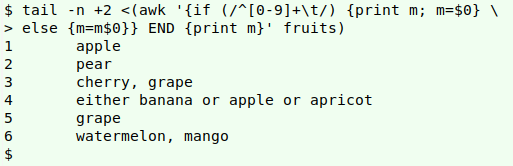
Ignore the tail command for a moment. AWK processes the file line by line, and looks to see whether or not the line begins with one or more numerals followed by a tab. If it does, AWK prints the variable "m" and resets the variable to the whole line. For the first line, that means an empty string is printed because "m" is an empty variable. It's that empty first output line that gets removed by the tail command after AWK has completely finished with the file.
When AWK finishes with line 1 and moves to line 2, "m" contains the whole of line 1. Since line 2 begins with a number, AWK prints line 1, then stores line 2 in "m". The same happens with line 3.
Line 4 ("grape") doesn't begin with a number, so AWK follows the "else" instruction for such lines, which is to reset "m" to equal its existing value ("3[tab]cherry, ") concatenated with the current line. "m" now contains "cherry, grape".
Line 5 again begins with a number, so AWK prints "3[tab]cherry, grape" and resets "m" to the contents of line 5.
And so on. In "fruits", however, the last line doesn't begin with a number, so nothing gets printed. When AWK reaches the end of the file, "m" contains "6[tab]watermelon, mango" from the concatenation of "6[tab]watermelon, " (line 10) and "mango" (line 11). "m" gets printed in an END statement.
Suppose the last line does begin with a number, say "7[tab]pear". Then when AWK reaches the last line, "m" would be "6[tab]watermelon, mango", and that's printed following the instruction for number-beginning lines. "7[tab]pear" is stored in "m", and that's printed in the END statement.
All-on-one-line
paste -s -d $'\x1b' fruits | sed -E 's/\x1b([0-9]+\t)/\n\1/g;s/\x1b//g'

The paste -s command puts the whole file on one line, with the original lines in the file separated (-d) by the invisible control character ESC (hex 1b). I use that character because it's unlikely to appear in any of the files I work with; there are other good choices among the C0 control characters.
Next, the one-line file is broken into separate lines. It's piped to sed -E, which first replaces all instances of (ESC followed by one or more numerals followed by a tab) with a newline followed by the numerals-tab string. This ensures that a numerals-tab string begins every line. Any remaining ESC characters must be separating the parts of a formerly broken line, and sed deletes those ESC characters.
I use the -E option for sed to allow it to see "+" not as the literal plus sign, but as the quantifier "1 or more", and also to do away with the need to escape parentheses when using backreferences like "\1": ([0-9]+\t) instead of \([0-9]+\t\).
Last update: 2020-06-03
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License