
For a full list of BASHing data blog posts, see the index page. ![]()
Quotes as characters (updated)
All BASH users have to know the important difference between single quotes and double quotes on the command line. Most users are probably also familiar with the workarounds sometimes needed to treat quotes as characters. To delete a single quote (= apostrophe), for example, you have to escape it, represent it by a code, or use a special command construct:
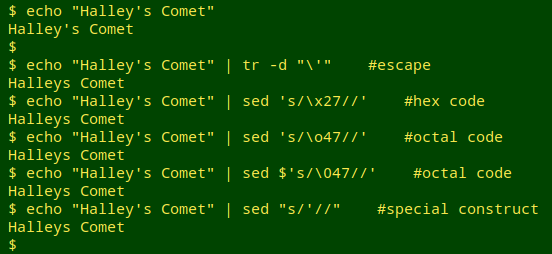
There are seven familiar variants on the two basic quote characters:
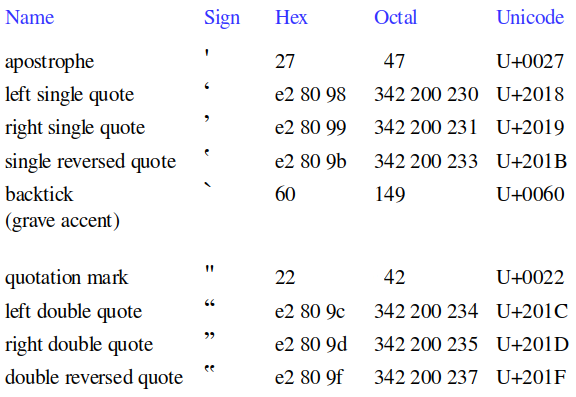
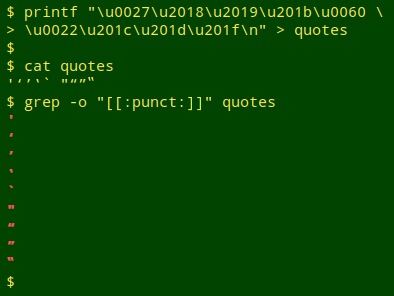
All nine of these quote characters are POSIX-classed as punctuation, where "punctuation" means "graphic characters other than letters and digits". This means that the quote variants can be searched for as [[:punct:]]:
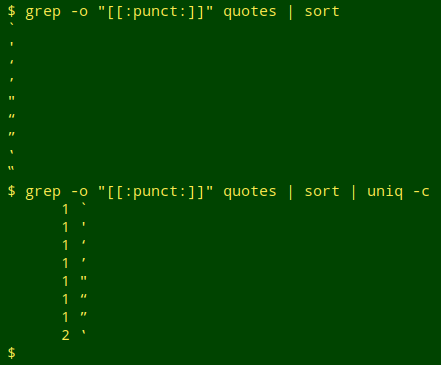
Most punctuation characters can be tallied in a file with sort and uniq -c. Unfortunately, the uniq command has a bug (the developers don't think it's a bug, apparently) which causes uniq to treat certain characters incorrectly. The double reverse quote is one of those characters:
A more complicated but safer way to do a punctuation tally is with AWK:
awk 'BEGIN {FS=""} {for (i=1;i<=NF;i++) if ($i ~ /[[:punct:]]/) {arr[$i]++}} END {for (j in arr) printf("%s\t%s\n",arr[j],j)}' quotes | sort -t $'\t' -k2
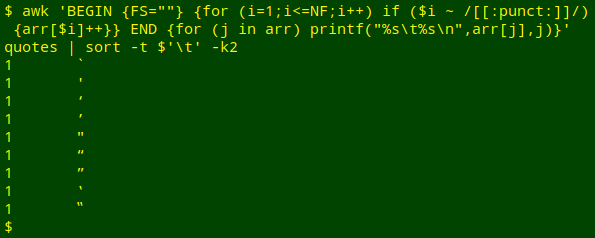
The BEGIN statement tells AWK that every character is a separate field. The main AWK command looks at each character in turn on each line. If a character matches something in the [[:punct:]] class, AWK adds that character to an array "arr", keeping a running total of the different items in the array with "++". When the file processing is done, the END statement tells AWK to go through the array item by item, printing first the total count of that item, then a tab, then the item. The printing is formatted by AWK's printf.
The AWK output is then sorted by the second column, the one with the characters.
It would be nice to know for certain which of the quote characters in a tally is which, for instance by appending the character's hex value. This can't be done simply with AWK, but you can do it by passing each quote character in the final tally to the hexdump command:
awk 'BEGIN {FS=""} {for (i=1;i<=NF;i++) if ($i ~ /[[:punct:]]/) {arr[$i]++}} END {for (j in arr) printf("%s\t%s\n",arr[j],j)}' quotes | sort -t $'\t' -k2 | while read -r line; do printf "%s\t%s" "$line"; cut -f2 <<<"$line" | hexdump -e '/1 "%02x" " "' | sed 's/ 0a //'; echo; done
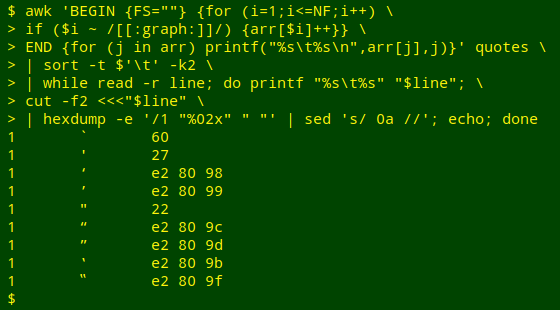
This command chain extends the AWK+sort command above. This revised version allows for correct processing of the "*" and "\" characters.
A while loop processes the AWK+sort output line by line. First, the whole line is printf-formatted so that the tally is followed by a tab, followed by the tallied character. There's no newline at the end of the formatting, so that whatever is done next is added directly to the growing output line.
In the second part of the while loop, the quote character is cut from the line and passed to hexdump with appropriate formatting options. The hexdump output is then stripped of its newline bytes and bracketing spaces (" 0a ") with sed and an echo is added to generate a final newline.
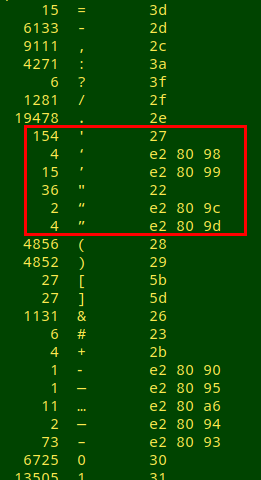
Here's the relevant part of the output from a data audit I did recently (formatted a little differently); the quote tallies are boxed in red. In this case I was tallying all graphic characters — [[:graph:]] instead of just [[:punct:]]. Note also the unmatched round brackets in the file being audited.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License