
For a full list of BASHing data blog posts, see the index page. ![]()
Putting information into a table from the table's filename
An example of this data-processing task would be grabbing the date part of a date-stamped filename and adding it to the table records (assuming they don't have a date), so that the files can be combined for a time-series study.
Below I use simplified files to make this task clearer. Each tab-separated file has the unit prices of 3 investments on a particular day. I'd like to combine the files after adding to each record the date given in the filename.
equities_05-Dec-2018.tsv:
| APIR code | Entry price | Exit price |
| MAQ0477AU | 0.9417 | 0.9372 |
| MAQ5378AU | 0.9503 | 0.9478 |
| MAQ0464AU | 1.0350 | 1.0322 |
equities_06-Dec-2018.tsv:
| APIR code | Entry price | Exit price |
| MAQ0477AU | 0.9286 | 0.9241 |
| MAQ5378AU | 0.9477 | 0.9452 |
| MAQ0464AU | 1.0321 | 1.0294 |
equities_07-Dec-2018.tsv:
| APIR code | Entry price | Exit price |
| MAQ0477AU | 0.9286 | 0.9241 |
| MAQ5378AU | 0.9376 | 0.9351 |
| MAQ0464AU | 1.0210 | 1.0183 |
To get the date part of the filename I can use AWK's "split" function:
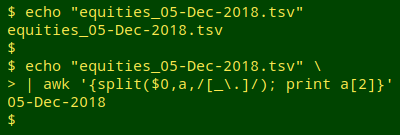
The "split" function is normally used with 3 arguments. The first is the string to be split, the second is the name of the array to be loaded with the split-out parts, and the third is the character used as a part-separator. However, that third argument doesn't have to be a literal character, like "_". It can also be a regex, and in this case the regex means "either underscore or period", with the "." escaped so that the regex engine doesn't interpret it as "any character".
And here's the first file by itself with a header line and a date added to each record:
awk 'BEGIN {split(ARGV[1],a,/[_\.]/)} NR==1 {print $0 "\t" "Date"} NR>1 {print $0 "\t" a[2]}' equities_05-Dec-2018.tsv
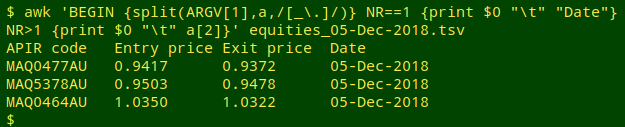
In order to grab the date part from the filename in the BEGIN statement, I use "ARGV[1]", which is the first argument offered to the AWK command, and in this case is the filename. To the first line of the file ("NR==1") AWK adds the tab-separated field name "Date". To all the remaining lines ("NR>1") AWK adds the tab-separated date part from the filename, stored in the array "a" as "a[2]".
Next I'll combine the 3 files into one table. First I print a header line with echo, then use a "for" loop to run the AWK command on just the non-header lines in each file:
echo -e "APIR Code\tEntry price\tExit price\tDate"; for i in *.tsv; do awk 'BEGIN {split(ARGV[1],a,/[_\.]/)} NR>1 {print $0 "\t" a[2]}' "$i"; done
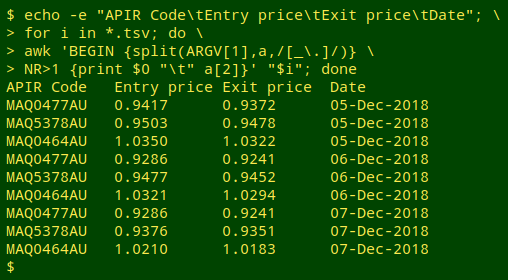
Not bad, but for ease of sorting the output table, it would be better if the dates were in ISO 8601 format, namely YYYY-MM-DD. Possibly the least fussy way to do this is to pipe the output table to a second AWK command, and use the date command "internally" to do the conversion:
echo -e "APIR Code\tEntry price\tExit price\tDate"; for i in *.tsv; do awk 'BEGIN {split(ARGV[1],a,/[_\.]/)} NR>1 {print $0 "\t" a[2]}' "$i" | awk 'BEGIN {FS=OFS="\t"} {"date -d "$4" +%Y-%m-%d" | getline iso; print $1,$2,$3,iso}'; done
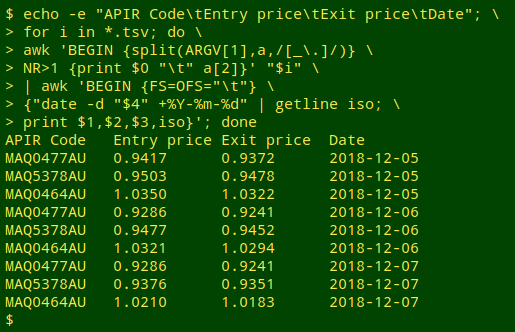
I rarely use the "command | getline" option in AWK, but in this case it's simpler than deconstructing the date and rebuilding it as YYYY-MM-DD. What happens here is that AWK allows the shell to run the command "date -d "$4" +%Y-%m-%d" (note the quotes in the command) and captures the output in the variable "iso". The date command recognises "05-Dec-2018" as a date and knows how to convert it.
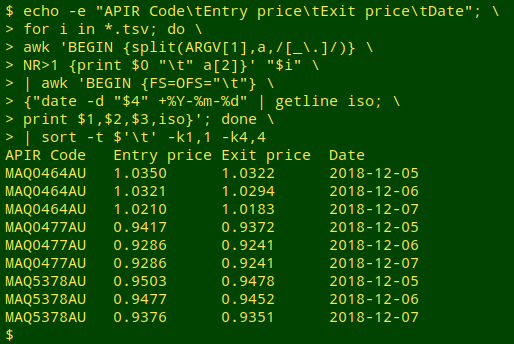
If wanted, that output table with ISO 8601 dates can be easily sorted by individual investments in chronological order:
echo -e "APIR Code\tEntry price\tExit price\tDate"; for i in *.tsv; do awk 'BEGIN {split(ARGV[1],a,/[_\.]/)} NR>1 {print $0 "\t" a[2]}' "$i" | awk 'BEGIN {FS=OFS="\t"} {"date -d "$4" +%Y-%m-%d" | getline iso; print $1,$2,$3,iso}'; done | sort -t $'\t' -k1,1 -k4,4
Last update: 2018-12-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License