
For a full list of BASHing data blog posts, see the index page. ![]()
Displaying data from table fragments
This post was inspired by a presentation I watched at a recent conference. The presenter had collected a large number of data tables, each of which had a selection of fields from a large pool of fields called Darwin Core Terms. How to neatly display which fields were in which tables?
The comma-separated file below is a simplified example. As you can see, a table can have a variable number of fields drawn from the same pool, and the order of the fields may vary.
tableA,fld4,fld3,fld1,fld5
tableB,fld2,fld3,fld4
tableC,fld1,fld2,fld5,fld3
tableD,fld3,fld1,fld4,fld5,fld2
tableE,fld3,fld5
tableF,fld4
tableG,fld3,fld1,fld4
There are different ways the layout problem could be tackled. Mine starts by generating a sorted, uniquified list of all the fields. This list is made into a "core" string which can then be attached to each of the table identifiers ("tableA", "tableB", etc). Before the attachment happens, I go through the file table by table and delete from the "core" any fields which are not present in the table.
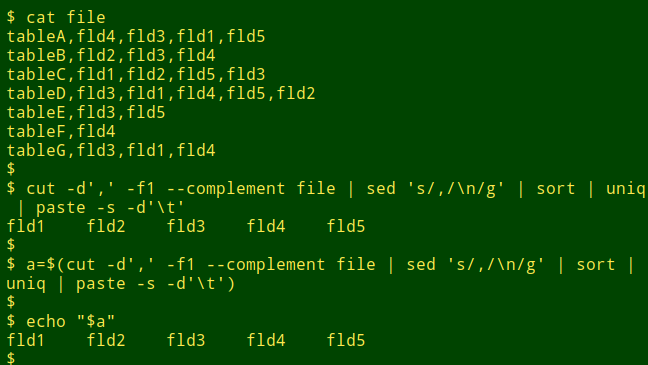
For the first step I use simple shell tools. The sorted, uniquified list is saved in a variable as a tab-separated string:
a=$(cut -d',' -f1 --complement file | sed 's/,/\n/g' | sort | uniq | paste -s -d'\t')
The second step is a single AWK command and prints to the screen a tidy layout of the fields in each table:
awk -F"," -v core="$a" 'BEGIN {split(core,arr,"\t")} {x=core; for (i in arr) if ($0 !~ arr[i]) sub(arr[i],"",x); print $1 FS x}' file
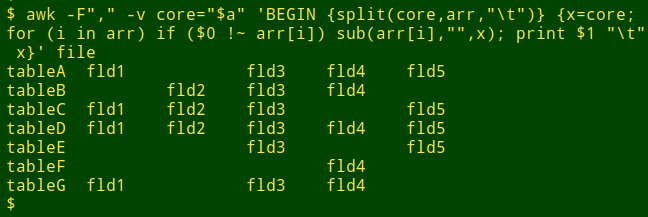
-F"," tells AWK that the file is comma-separated
-v core="$a" assigns the shell variable "a" to the AWK variable "core"
BEGIN {split(core,arr,"\t")} splits the tab-separated string "core" into its different parts in the array "arr", making arr[1] = fld1, arr[2] = fld2, etc
x=core resets the string "x" to be the same as "core" at the start of each line that AWK processes
for (i in arr) is a loop in which AWK checks each of the array elements
if ($0 !~ arr[i]) is a test in which AWK looks to see if the array element is missing from the line being processed
sub(arr[i],"",x) AWK replaces any array element found to be missing with a blank ("") in the string "x"
print $1 FS x: with the "for" loop finished and missing elements blanked out in "x", AWK now prints for each line the identifier field, a tab and the modified "x"
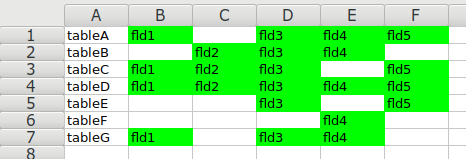
The output is easily copy/pasted into a spreadsheet (or opened in a spreadsheet as a new file) and conditionally formatted:
If wanted, a follow-up AWK command would build a pivot table from the output:
[previous command] | awk -v core="$a" 'BEGIN {FS=OFS="\t";print "Table\t"core} {for (j=2;j<=NF;j++) if ($j != "") $j="used"} 1'
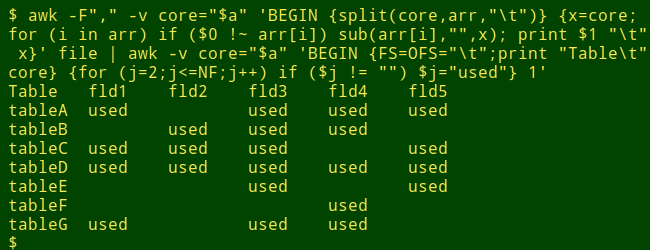
The second AWK command first prints a table header, composed of the fieldname "Table", a tab and the "core" string. AWK then loops through the fields in each line, ignoring the first field (with the table identifier), and replacing non-blank items like "fld1" with the string "used".
And if you're a dyed-in-the-wool shell user, you could even colorise that pivot table!
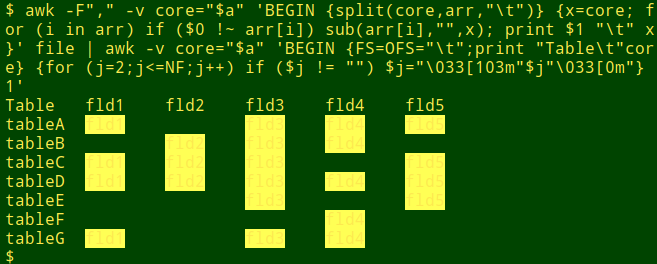
I cheated a little here. My terminal prints text in yellow, so I made the background of non-blank data items light yellow with the ANSI escape colouring "\033[103m" and reset the background with "\033[0m". The data items are still just visible...
Last update: 2019-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License