
For a full list of BASHing data blog posts, see the index page. ![]()
Time series ops
A time series is a great source of data for command-line manipulations if it's well-formed. By "well-formed" I mean it's a plain text file with one record per line, there are no blank lines, each date/time is unique and every date/time has a non-blank data item associated with it.
The "demo" file below has three tab-separated columns with date, time and cash amount. I'll do some simple queries on this table, and you'll have to imagine that the table is actually much longer and I couldn't just get the answers by inspection!
| 2018-07-10 | 08:21 | 32.33 | |
| 2018-07-10 | 12:19 | 36.54 | |
| 2018-07-10 | 14:01 | 79.26 | |
| 2018-07-10 | 17:43 | 50.64 | |
| 2018-07-10 | 19:10 | 34.96 | |
| 2018-07-11 | 10:01 | 71.37 | |
| 2018-07-11 | 13:48 | 13.33 | |
| 2018-07-11 | 16:22 | 18.33 | |
| 2018-07-11 | 19:55 | 62.24 | |
| 2018-07-12 | 08:52 | 59.84 | |
| 2018-07-12 | 09:19 | 66.00 | |
| 2018-07-12 | 12:27 | 9.30 | |
| 2018-07-12 | 13:40 | 20.64 | |
| 2018-07-12 | 13:41 | 74.92 | |
| 2018-07-12 | 14:57 | 79.85 |
The first query is: What was the first record on each date?
awk -F"\t" '$1==a {next} $1!=a {print; a=$1}' demo

Here AWK stores the contents of the first field (the date) in the variable "a", and tests to see if the first field in the next record is the same as what's stored in "a". If it is, AWK moves to the next record. If it isn't, AWK prints the record and resets "a" to the new, different first field.
What was the last record on each date?
tac demo | awk -F"\t" '$1==a {next} $1!=a {print; a=$1}' | tac

Same AWK command, just run it on the file with the line-order reversed with tac, and line-reverse the output.
What was the biggest cash amount on each date, and when was it recorded?
awk -F"\t" '!($1 in a) || a[$1]<$3 {a[$1]=$3; b[$1]=$2} \
END {for (i in a) print i FS b[i] FS a[i]}' demo | sort

AWK stores the cash amount in the array "a", indexed by the date. If the cash amount is bigger than the stored amount, the array is re-defined with that larger amount; the time is stored in a second array "b". After the file has been processed line by line, AWK prints the dates and times and cash amounts in the arrays. The array output is then date-sorted with sort. Following the excellent advice of AWK guru Ed Morton, the array "a" is initialised with the first cash amount.
If you're running GNU AWK 4, you can sort the array output within the AWK command by putting PROCINFO["sorted_in"] = "@ind_num_asc" in the BEGIN or END statement. I think I prefer sort...
What was the smallest cash amount on each date, and when was it recorded?
awk -F"\t" '!($1 in a) || a[$1]>$3 {a[$1]=$3; b[$1]=$2} \
END {for (i in a) print i FS b[i] FS a[i]}' demo | sort

Same AWK command, just change the "less than" sign to a "greater than" sign when testing field 3 against the array "a".
What was the total cash amount on each date?
awk -F"\t" '{c[$1]+=$3} \
END {for (i in c) print i FS c[i]}' demo | sort
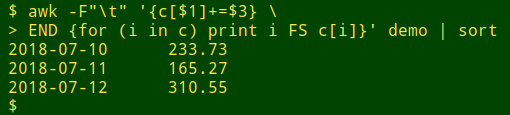
AWK adds up the total cash amount and stores it in an array "c" indexed by date.
What was the average cash amount on each date?
awk -F"\t" '{d[$1]++; c[$1]+=$3} \
END {for (i in d) printf("%s\t%.2f\n",i,c[i]/d[i])}' demo | sort
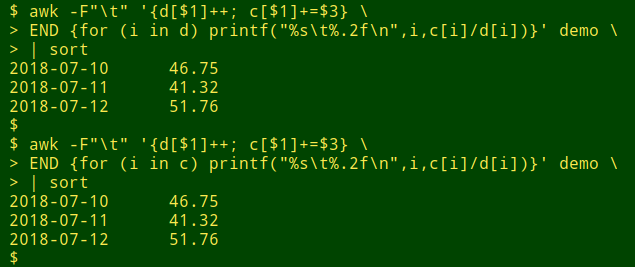
AWK stores the number of records for each date in the array "d" and divides each daily cash amount total by that number. "printf" is used here to round the average to 2 decimal places. Note that in "walking through" the arrays in the END statement, you can use either the "c" or "d" array in "for (i in array)", because both arrays are indexed by date.
Now for a handy trick with AWK's substring function. I have a file "spr1" with daily rainfall totals for the St Pauls River in eastern Tasmania, for the 10 years from the start of 2008 to the end of 2017. It's a tab-separated, 2-field file with the ISO 8601 date and the rainfall in mm:
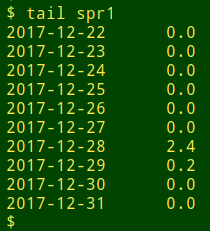
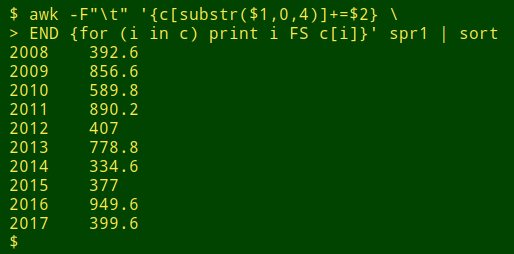
To get the total rainfall in each year, I use the same AWK command I used above to get the total cash amount on each date, but this time I index the array with just the year portion of the date, extracted with "substr":
awk -F"\t" '{c[substr($1,0,4)]+=$2} \
END {for (i in c) print i FS c[i]}' demo | sort
And the average monthly rainfall over the 10 years?
awk -F"\t" '{c[substr($1,6,2)]+=$2} \
> END {for (i in c) printf("%s\t%.1f\n",i,c[i]/10)}' spr1 | sort
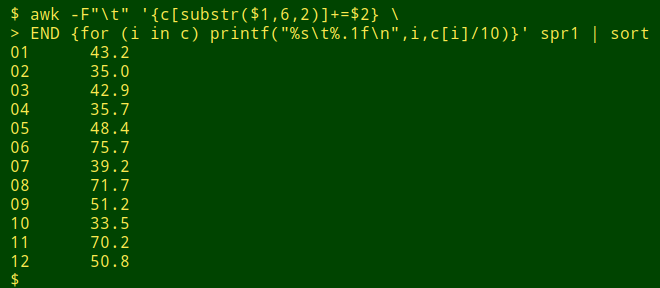
Or a little more understandably:
awk -F"\t" '{c[substr($1,6,2)]+=$2} \
END {for (i in c) printf("%d\t%.1f\n",i,c[i]/10)}' spr1 | sort -n \
| awk -F"\t" 'BEGIN \
{split("Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec",m,",")} \
{sub($1,m[$1])} 1'
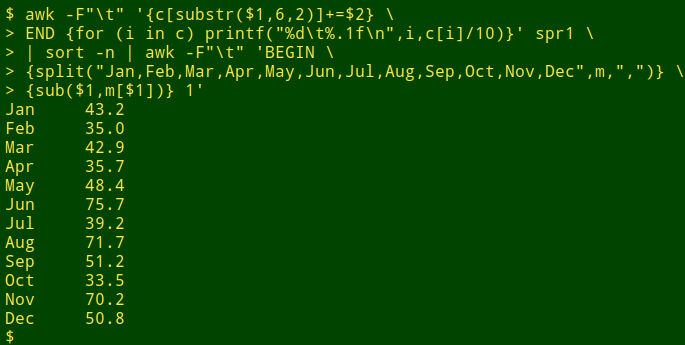
This time "printf" prints the months as numbers without leading zeroes and sort does the sorting numerically, from 1 to 12. The output is then sent to a second AWK command which starts by using "split" to fill an array "m" with month abbreviations, in numerical order. In other words, the value of "m[1]" is "Jan", "m[2]" is "Feb", and so on. The "sub" function then substitutes month abbreviations for month numbers in the output table.
Last update: 2018-07-23
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License