
For a list of BASHing data 2 blog posts see the index page. ![]()
Format musings 2: CSV vs KVR (key-values in rows)
Everyone knows the CSV file format, except they probably don't.
The field separator has to be a comma? Nope. So-called ".csv" files often have a colon, semicolon or tab as field separator. The first line needs to have fieldnames? Nope. That's optional, according to the relevant RFC spec (RFC 4180).
Details aside and ignoring the world of Big Data, CSV is probably the world's most widely used file format for sharing data tables. It has some annoyances, though, of which the biggest (in my mind) is that commas and quotes within data items need to be escaped. Another issue is that the field to which a data item belongs may not be obvious when you're looking at some random line in a ten-thousand-row, 20-column CSV.
A CSV alternative is what I call a "KVR" (key-values in rows) file, in which each row has a horizontal list of key-value pairs. There's no need to escape characters within data items and each value is preceded by its key, so you always know what each value means. Here's a sample CSV, "records":
Trans,CustID,Date,Sale
001,c563,20250201,$45.90
002,c772,20250201,$66.25
003,c563,20250202,$39.50
004,c681,20250203,$119.00
And below is the same data presented as a KVR. For this demo the field separator is a "pipe" and the key-value separator is a "colon". Those are not what they look like. They're actually two characters that are unlikely to appear in data items, namely box drawings light vertical (U+2502, hex e2 94 82) and Armenian full stop (U+0589, hex d6 89).
Trans։001│CustID։c563│Date։20250201│Sale։$45.90
Trans։002│CustID։c772│Date։20250201│Sale։$66.25
Trans։003│CustID։c563│Date։20250202│Sale։$39.50
Trans։004│CustID։c681│Date։20250203│Sale։$119.00
Note that the row arrangement in the CSV is preserved. It's a hierarchical sort of arrangement that could also be formatted in XML or JSON, but KVR formatting is more compact, and to my eyes more understandable.
How do you go from a CSV without quote escapes to a KVR?
Being an enthusiastic AWKist, to get to a KVR I would reformat an escape-free CSV with AWK:
awk -F"," 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i; next} {for (j=1;j<=NF;j++) $j=a[j]"\xd6\x89"$j} 1' OFS="\xe2\x94\x82" records
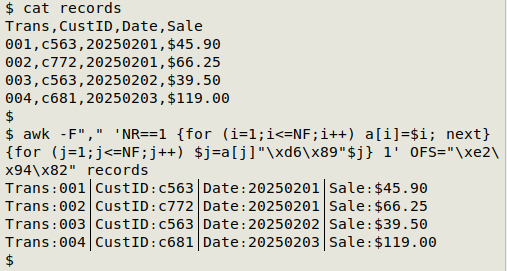
The input field separator is a comma (-F",") and the output field separator is the "box drawings light vertical" character (OFS="\xe2\x94\x82").
AWK first looks at the first (header) line (NR==1) and works through it field by field (for (i=1;i<=NF;i++)), building an array "a" indexed with the field number and with the field name as the value associated with that field number (a[i]=$i).
Having finished with the first line, AWK moves to the next line (next). Here and in all subsequent lines, AWK works through the line field by field (for (j=1;j<=NF;j++)) and redefines the field value as the field name from the array "a", an "Armenian full stop" character and the existing field value ($j=a[j]"\xd6\x89"$j).
Finally, the instruction "1" (meaning print the line if 1 is true, and it is) gets all lines printed with their new values, or the existing values in the case of the header, and with the new field separator.
What if the CSV has escapes?
Date,Time,Appointment
26 Oct,1500,"dentist, book next appt"
27 Oct,1000,"meet Jeff at ""Baker's"", Dunwich"
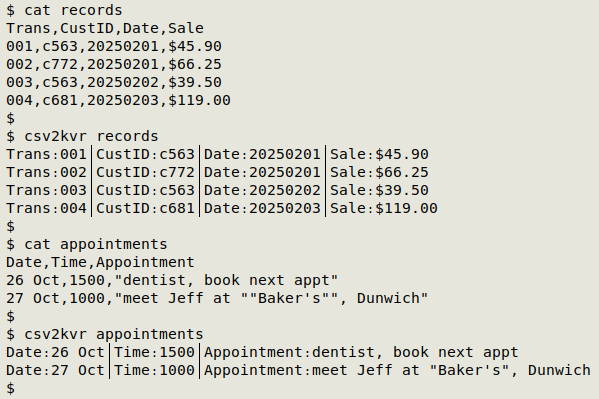
I do hate CSV escapes, which create trouble even when they're done correctly according to the RFC for CSVs. Anyway, I can modify the c2t function from A Data Cleaner's Cookbook so that it replaces field-separating commas with the invisible control character U+0001 (hex 01), then pass the result to the AWK command above, with the input field separator set to that invisible character. I'll store all this in the "csv2kvr" function:
csv2kvr() { sed 's/""/@@@/g' "$1" | awk -v FPAT='[^,]*|"[^"]*"' -v OFS="\x01" '{$1=$1; gsub(/"/,""); print}' | sed 's/\x01@@@\x01/\x01\x01/g;s/@@@/"/g' | awk -F"\x01" 'NR==1 {for (i=1;i<=NF;i++) a[i]=$i; next} {for (j=1;j<=NF;j++) $j=a[j]"\xd6\x89"$j} 1' OFS="\xe2\x94\x82"; }
How do you get from a KVR to a TSV?
With AWK, and using sed to remove line-ending tabs:
kvr2tsv() { awk -F"[\xd6\x89|\xe2\x94\x82]" 'NR==1 {for (i=1;i<=NF;i+=2) printf("%s\t",$i); print ""} NR>1 {for (i=2;i<=NF;i+=2) printf("%s\t",$i); print ""}' "$1" | sed 's/\t$//'; }
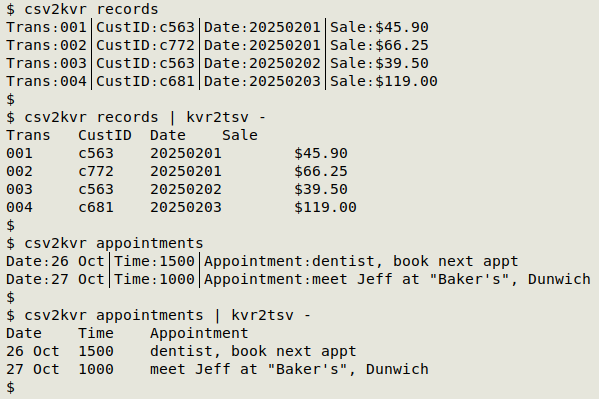
AWK is told with -F"[\xd6\x89|\xe2\x94\x82]" that the field separator in the KVR file is either a "colon" or a "pipe".
On the first line (NR==1) AWK works though field by alternate field (for (i=1;i<=NF;i+=2) and prints each key followed by a tab (printf("%s\t",$i)), then a new line (print "").
On subsequent lines (NR>1) AWK does the same with values, ignoring the keys. The last command (sed 's/\t$//') deletes the tab at the end of each output line.
Next post:
2025-11-21 THE escape character, not AN escape character
Last update: 2025-11-14
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License