
For a list of BASHing data 2 blog posts see the index page. ![]()
Beware these characters in a terminal
Back in 2018, I showed in a BASHing data post that printing a Single Character Introducer (SCI) in a terminal emulator could unexpectedly generate a mass of "c62;" strings followed by a hang (you didn't return to a prompt). This strange result appeared in gnome-terminal and xfce4-terminal, but not in xterm. An IT security professional, Timothy Bolton, wrote to me in 2018 that
printf "\x1b\x5b\x35\x63"
likewise pumped out "c62;", and although I could confirm it at the time, I can't now. Instead, in the terminal emulators I've tried in 2025, the SCI simply hides the next character, and Bolton's string does nothing. Here's how that looks in my usual emulator, sakura (3.8.6); I get the same result with xfce4-terminal (1.1.3):

I wrote "hides" because the next character isn't really deleted, as can be seen in a text editor:
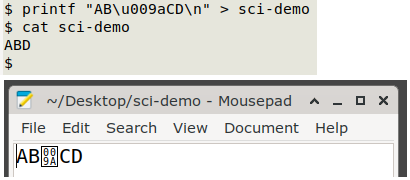
I have no idea why the 2018 and 2025 results are different. In both years my machines were running Debian stable as a base with the en_AU.UTF-8 locale.
The following table shows what happens when I print each of the C0 and C1 control characters within the string AB[control character]CD\n in sakura.
| Acronym | Name | Unicode | Effect |
| C0 | |||
| NUL | Null | U+0000 | none |
| SOH | Start of heading | U+0001 | none |
| STX | Start of text | U+0002 | none |
| ETX | End of text | U+0003 | none |
| EOT | End of transmission | U+0004 | none |
| ENQ | Enquiry | U+0005 | none |
| ACK | Acknowledge | U+0006 | none |
| BEL | Bell | U+0007 | none |
| BS | Backspace | U+0008 | hides previous character |
| HT | Horizontal tabulation | U+0009 | adds tab character |
| LF | Line feed | U+000A | starts new line with next character |
| VT | Vertical tabulation | U+000B | starts new line with next character at its previous horizontal position |
| FF | Form feed | U+000C | starts new line with next character at its previous horizontal position |
| CR | Carriage return | U+000D | adds newline, hides preceding characters |
| SO | Shift out | U+000E | none |
| SI | Shift in | U+000F | none |
| DLE | Data link escape | U+0010 | none |
| DC1 | Device control 1 | U+0011 | none |
| DC2 | Device control 2 | U+0012 | none |
| DC3 | Device control 3 | U+0013 | none |
| DC4 | Device control 4 | U+0014 | none |
| NAK | Negative acknowledge | U+0015 | none |
| SYN | Synchronous idle | U+0016 | none |
| ETB | End transmission block | U+0017 | none |
| CAN | Cancel | U+0018 | none |
| EM | End of medium | U+0019 | none |
| SUB | Substitute | U+001A | appears as � |
| ESC | Escape | U+001B | hides next character |
| FS | File separator | U+001C | none |
| GS | Group separator | U+001D | none |
| RS | Record separator | U+001E | none |
| US | Unit separator | U+001F | none |
| C1 | |||
| PAD | Padding character | U+0080 | none |
| HOP | High octet preset | U+0081 | none |
| BPH | Break permitted here | U+0082 | none |
| NBH | No break here | U+0083 | none |
| IND | Index | U+0084 | starts new line with next character at its previous horizontal position |
| NEL | Next line | U+0085 | starts new line with next character |
| SSA | Start of selected area | U+0086 | none |
| ESA | End of selected area | U+0087 | none |
| HTS | Horizontal tabulation set | U+0088 | none |
| HTJ | Horizontal tabulation with justification | U+0089 | adds tab character |
| VTS | Vertical tabulation set | U+008A | none |
| PLD | Partial line down | U+008B | none |
| PLU | Partial line up | U+008C | none |
| RI | Reverse index | U+008D | rewrites entry (see below) |
| SS2 | Single shift 2 | U+008E | none |
| SS3 | Single shift 3 | U+008F | none |
| DCS | Device control string | U+0090 | hides next characters, including newline |
| PU1 | Private use 1 | U+0091 | none |
| PU2 | Private use 2 | U+0092 | none |
| STS | Set transmit state | U+0093 | none |
| CCH | Cancel character | U+0094 | none |
| MW | Message waiting | U+0095 | none |
| SPA | Start protected area | U+0096 | none |
| EPA | End protected area | U+0097 | none |
| SOS | Start of string | U+0098 | hides next characters, including newline |
| SGCI | Single graphic character introducer | U+0099 | none |
| SCI | Single character introducer | U+009A | hides next character |
| CSI | Control sequence introducer | U+009B | inserts itself invisibly, hides next character |
| ST | String terminator | U+009C | none |
| OSC | Operating system command | U+009D | hides next characters, including newline |
| PM | Privacy message | U+009E | hides next characters, including newline |
| APC | Application program command | U+009F | hides next characters, including newline |
I worry about the characters with something other than "none" for an effect, because I do data auditing in a terminal, and I've found almost all the C0 and C1 characters lurking in text files at one time or another. Most of the time they're part of mojibake arising from a failed encoding conversion. I can't simply delete the control characters — I need to work out what the original characters were before the mojibake-ing.
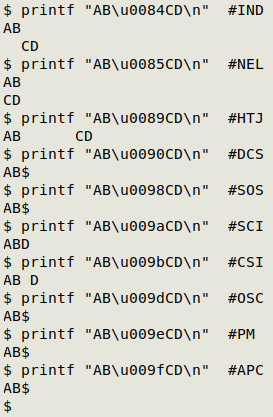
Below I show the "effective" C1 characters at work, except RI:
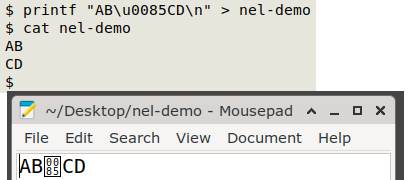
This is, of course, only how the strings look in a terminal. The NEL control character, for example, doesn't really generate a newline, as shown in a text editor:
RI is a special and very weird case. The two screenshots below show what my terminal looks like before and after pressing Enter:

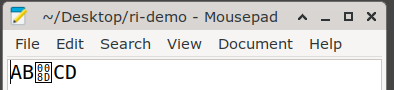
Once again, the output looks fine in a text editor if saved as "ri-demo":
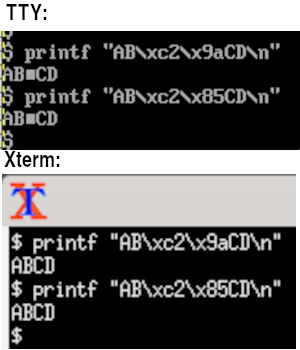
Summing up. I haven't tried every modern terminal emulator, but the ones I've looked at will all interpret a C1 control character as though they were ANSI-standard teletype machines. This is annoying behaviour when working with text files in a terminal. In contrast, neither a TTY nor the venerable xterm pay attention to the meaning of the C1 control characters:
Next post:
2025-06-27 Five ways to pass a shell variable to AWK
Last update: 2025-06-20
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License