
For a list of BASHing data 2 blog posts see the index page. ![]()
Multiple-line records to a simple table
The text below (filename "stack") is a hugely simplified version of a big file I worked with some months back. As in "stack", the file was easily readable because every blank-line-separated item had the same format. In "stack" that format is some pipe-separated text (line 1), some numbers (line 2), the string "Fruits:" (line 3), and then a variable number of lines, each of which has a fruit name.
abc|def
123
fruits:
apple
pear
banana
ghi|jkl
456
fruits:
melon
mno|pqr
789
fruits:
apricot
peach
I wanted to transform the big table into something more easily parsed and sorted. For "stack", that new format might be:
abc|def|123|apple
abc|def|123|pear
abc|def|123|banana
ghi|jkl|456|melon
mno|pqr|789|apricot
mno|pqr|789|peach
The command I used to do this was fairly simple:
awk 'BEGIN {FS="\n";OFS="|";RS="";ORS="\n"} {for (i=4;i<=NF;i++) print $1 OFS $2 OFS $i}' stack
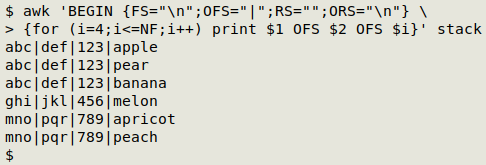
AWK looks at "stack" to BEGIN with and sees records separated by a blank line (RS="") and fields separated by a newline (FS="\n"). AWK then loops through the fields (lines) in each record beginning with field 4, which is the first fruit line (for (i=4;i<=NF;i++)). Before finishing with each field (fruit line) AWK prints the first field in the record (the pipe-separated letters line), the second field (the numbers line) and the fruit line, but it separates these fields with the output field separator, which is a pipe (OFS="|"). AWK does this for each blank-line-separated record in turn, but it separates the records in the output with the output record separator, which is a newline (ORS="\n").
Next post:
2025-05-23 How to ignore everything but numbers
Last update: 2025-05-16
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License